@半监督神经原始语言重构Semisupervised Neural Proto-Language Reconstruction
摘要
- 现有原型语言(祖先语言)比较重构工作通常需要完全监督。
- 本文提出一种半监督历史重构任务:
- 模型仅使用少量标记数据(带有原型形式的同源集)和大量未标记数据(无原型形式的同源集)进行训练。
- 提出了一种神经网络架构(DPDBiReconstructor),基于比较法核心洞见:
- 重构词不仅需从子语言词重构而来,还需能确定性地转换回子语言词。
- 实验表明,该架构能利用未标记同源集,在此新任务上显著优于强半监督基线。
1 引言
- 19世纪欧洲语言学家发现:
- 语言变化具有系统性,可通过比较法重构无记录的原型语言。
- 比较法基于“规律性原则”(Neogrammarian假说):
- 音变按无例外的规律进行,同一语言社区内方向一致。
- 示例引述(Brugmann和Osthoff,1878):
“每个机械进行的音变均按无例外规律完成……所有符合条件的词均受影响。”
- 比较法对人类应用具有挑战性:
- 数据量大,需平衡重构词与后代词的语音相似性及音变规律性。
- 现有监督重构模型多为序列到序列转换,需大量标记数据:
- 仅在语言学家完成大部分音变识别后实用。
- 本文提出半监督原型形式重构任务:
- 模拟早期历史语言学家场景,仅用少量标记同源集和大量未标记数据。
- 与半监督机器翻译不同,无目标语言单语数据。
2 方法
2.1 模型

- 提出多任务重构策略DPD-BiReconstructor:
- 包含子网络:
- D2P(子语言到原型形式)
- P2D(原型形式到子语言)
- 共享音素嵌入。
- 包含子网络:
- 训练方式:
- 标记数据:学习准确重构到后代的音变。
- 未标记数据:通过后代预测提供弱监督。
- 架构特点:
- D2P最终解码器状态通过桥接网络连接至P2D编码器。
- 损失函数:
- 标记数据:D2P和P2D的交叉熵损失(
, )。 - 所有数据:基于预测原型形式的后代预测损失(
, )。 - 附加余弦相似性损失训练桥接网络。
- 标记数据:D2P和P2D的交叉熵损失(
- CRINGE损失防止P2D从错误原型形式预测正确后代。
2.2 半监督策略
- 基线:
- 监督仅策略(SUPV):丢弃未标记数据。
- Bootstrapping(BST):将高置信度预测作为伪标签。
- Π-模型(ΠM):从同一个训练示例中创建两个随机增强的输入,将这两个增强的输入馈入模型,并最小化两个输出之间的均方差来优化模型的一致性
- 对于连续的输入(比如图片这种可以连续变化的数据),随机增强很简单:可以直接加点噪声(noise),比如在图片上加些随机噪点。
- 但对于音素这种离散的输入,加噪声可能会让它们变得没意义(比如“p”变成某种中间状态),这会破坏语言学的规律。作者提出了一个替代方案:对同源集(cognateset) 进行随机增强。即随机打乱reflexes的顺序,或随机去掉一些子语言daughter languages
- 组合策略:
- DPD与BST、ΠM可组合,形成8种策略:
- SUPV, BST, ΠM, ΠM-BST, DPD, DPD-BST, DPD-ΠM, DPD-ΠM-BST。
- DPD与BST、ΠM可组合,形成8种策略:
- 架构选择:
- GRU(基于Meloni et al., 2021)和Transformer(基于Kim et al., 2023)。
2.3 实验
- 数据集:
- Romphon(拉丁语重构,Meloni et al., 2021)。
- WikiHan(中古汉语重构,Chang et al., 2022)。
- 通过隐藏部分标签模拟半监督场景。
- 实验设置:
- 跨策略比较:固定10%标记数据,重复4组随机种子。
- 跨标记比例比较:测试5%、10%、20%、30%标记比例。
- 单调子集选择约束:如果
(比如5% ≤ 10%),那么 必须是 的子集。也就是说,5%的标签集一定包含在10%的标签集里,10%的标签集一定包含在20%的标签集里,以此类推。
- 单调子集选择约束:如果
- 评估指标:
- 词素编辑距离(TED)、词素错误率(TER)、准确率(ACC)、特征错误率(FER)、B-Cubed F分数(BCFS)。
- 统计检验:
- Wilcoxon秩和检验及Bootstrap均值差异检验,显著性阈值
。
- Wilcoxon秩和检验及Bootstrap均值差异检验,显著性阈值
3 结果
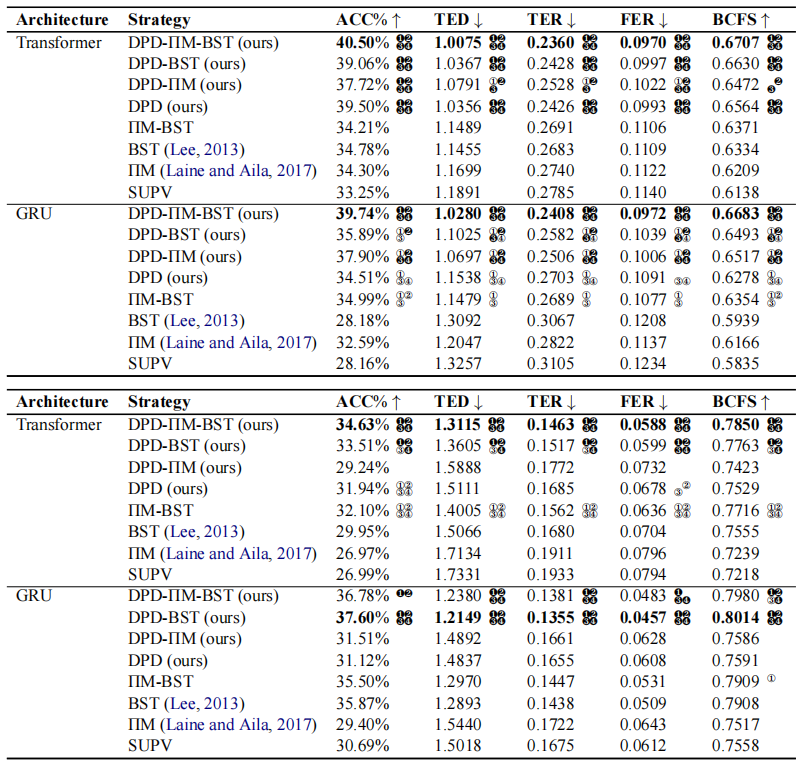
- 跨策略比较(表2):
- WikiHan:DPD-ΠM-BST在ransformer和GRU上最佳,显著优于所有基线。
- Rom-phon:Transformer上DPD-ΠM-BST最佳,GRU上DPD-BST最佳。
- 作者的实验表明,在半监督环境下,即使数据量较少(10%标签),Transformer在WikiHan上仍然表现更好。这挑战了Kimetal。对Transformer和RNN数据需求的假设。
- Kim et al. 的研究是在全监督学习环境下进行的,他们发现:
- Transformer 在 Rom-phon 数据集上优于 Meloni et al. (2021) 的 GRU 模型。
- 但在 WikiHan 数据集上,Transformer 表现不如 GRU。
- 然而,在作者的10%标签半监督环境下,结果却相反:
- Transformer 在 WikiHan 上优于 GRU。
- GRU 在 Rom-phon 上优于 Transformer。
- 这与 Kim et al. (2023) 的假设相矛盾。Kim et al. 认为:
- Transformer 模型需要更多数据才能发挥作用。
- RNN(如GRU)在数据较少时表现更好。
- Kim et al. 的研究是在全监督学习环境下进行的,他们发现:
- 数据集组之间的性能差异
- 不同数据集组(即不同的标签子集)之间的性能差异很大。这与他们的假设一致:访问不同的标签子集会显著影响学习结果。
- 不同标签设置下的性能(Performance for varied labeling settings)
- DPD策略在低标记比例(5%)下表现突出,如GRU-DPD-ΠM-BST在WikiHan上准确率近倍增。
- 高标记比例(30%)接近全监督模型性能。
4 分析
4.1 DPD训练
作者进行了一项消融实验,移除了CRINGE损失,并保持其他超参数和模型初始化不变,以观察其对训练的影响。
- 有无CRINGE损失的对比:
- 无论是否使用CRINGE损失,从正确的原型形式重构后预测后代语言的准确率始终更高。这验证了作者的假设:更好的后代语言重构能促进更好的原型形式重构。
- CRINGE损失的具体影响:
- 在早期训练阶段(epochs),启用CRINGE损失时,从错误原型形式预测后代语言的准确率略有下降。
- 但同时,从正确原型形式预测的准确率也略有降低。
- 超参数重要性:
- CRINGE损失的权重在实践中被认为是一个相对不重要的超参数,对整体性能的影响有限。
4.2 后代预测性能
- 半监督性能:
- 即使只有少量标签(如小百分比),半监督后代语言预测的性能也接近全监督性能。
- 这与假设一致:从原型到后代语言的音变(sound changes)更容易建模。
- 金标准原型形式的依赖性:
- 基于金标准原型形式预测后代语言的性能受相应损失权重的调节。
- 一些最佳DPD模型在P2D子网络上对金标准原型形式的表现较差。
- 结论:
- P2D在训练中辅助D2P的能力,并不依赖于P2D在金标准原型形式上的预测性能。
4.3 学习到的音素表示
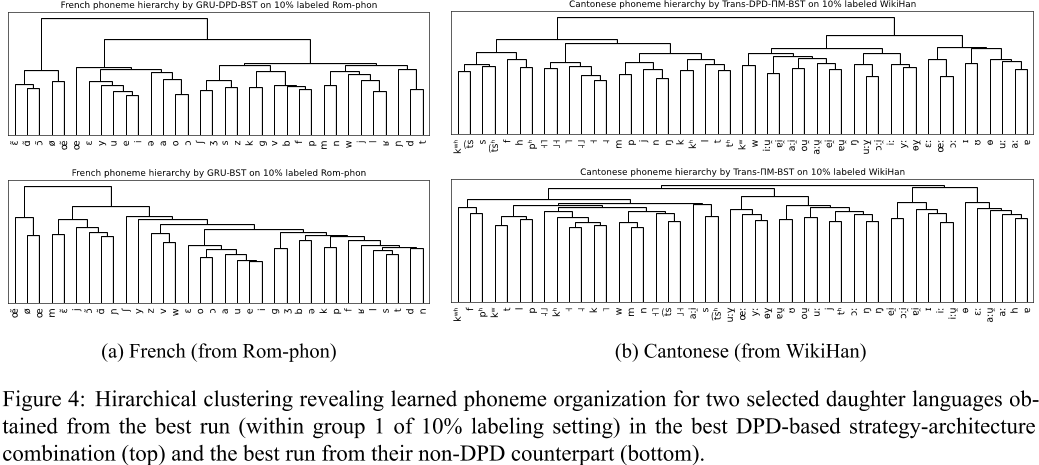
使用Ward方差最小化算法(一种层次聚类方法)分析音素嵌入的层次组织。图4展示了两种语言(法语和粤语)的音素组织结果,比较了DPD-based模型(如GRU-DPD-BST和TransDPD-ΠM-BST)与非DPD模型(如GRU-BST和Trans-ΠM-BST)。
- DPD策略音素嵌入更具语言学意义(图4):
- 法语:元音与辅音清晰分离。
- 粤语:声调聚类更一致。
4.4 未标记数据消融
- 通过消融实验研究半监督策略的性能提升是否来源于对无标签同源集的有效利用。
- 在10%标签设置下,去除所有无标签训练数据,模拟小型监督训练集。
- 比较ΠM、DPD、DPD-ΠM与监督基线(SUPV)的性能。
- 无标签数据的影响:
- 没有无标签数据时,ΠM、DPD和DPD-ΠM有时仍显著优于SUPV。
- 但几乎总是显著劣于使用无标签数据或结合Bootstrapping时的性能。
- 可能的解释:
- ΠM、DPD和DPD-ΠM能从有标签和无标签数据中有效学习。
- 在仅有标签数据时,DPD中的P2D仍能为D2P提供信息。
- Π-model的随机数据增强可能增强了有标签样本。
4.5 监督重构应用
- DPD和ΠM在全监督场景下优于SUPV,部分指标超现有方法(表15)。
5 相关工作
- 计算历史语言学:
- 原型重构和后代预测为核心任务。
- 方法包括规则系统、概率模型、神经网络等。
- 半监督学习:
- 代理标签和一致性正则化为主流方法。
- 本任务无单语数据,与半监督机器翻译不同。
6 结论
- 提出半监督重构任务及DPD-BiReconstructor架构。
- 在稀疏标记场景下显著优于基线,验证比较法的计算实现潜力。
局限性
- 实验局限于10%标记的WikiHan和Rom-phon数据集。
- DPD音变学习机制尚需进一步解释。
- P2D对错误原型形式后代预测仍较准确,需改进。
- Π-模型仅使用简单噪声策略,未来可优化。