@句嵌入追踪思想谱系Tracing the Genealogies of Ideas with Sentence Embeddings
摘要
I introduce an approach which leverages a sen-tence embedding index to efficiently search for similar ideas in a large historical corpus. This method remains robust in conditions of high OCR error found in real mass digitized his-torical corpora that disrupt previous published methods, while also capturing paraphrase and indirect influence.
I evaluate this method on a large corpus of 250,000 nonfiction texts from the 19th century, and find that discovered influence is in line with history of science literature. By expanding the scope of our search for influence and the origins of ideas beyond traditional structured corpora and canonical works and figures, we can get a more nuanced perspective on influence and idea dissemination that can encompass epistem-ically marginalized groups.【我用19世纪的25万篇非小说文本对这种方法进行了评估,发现所发现的影响符合科学文献的历史。通过将影响和思想来源的研究范围扩大到传统的结构化语料库、经典作品和人物之外,我们可以获得一个更微妙的观点,这种观点可以涵盖知识上边缘化的群体。 】
- 提出新型思想影响力检测方法:
- 技术基础:采用句子嵌入索引(GTE-small)实现大规模历史语料库检索
- 核心优势:
- 对OCR错误具有强鲁棒性(7-20%字符错误率下仍保持90%相似度)
- 支持转述识别与间接影响检测
- 验证结果:
- 在25万本19世纪非虚构文本中验证
- 发现模式与科学史文献记载一致
引言和相关工作
研究背景
- 思想传播分析困境:
- 传统文学分析案例:Darwin's Plots揭示跨学科影响网络
- 专家知识局限性:无法覆盖百万级文本的跨学科分析
- 现有方法不足:
- 主题模型:缺乏具体论点粒度
- 文本重用:仅限直接引用检测,需要高算力,ocr 鲁棒性
- 词义演变:难以跨词进行内容捕捉分析,敏感于语言变化
- 技术路线:
- 通过句子级嵌入整合文本复用检测与词义相似度分析
数据与方法
语料库构建
- 数据来源: 英国皇家学会、林奈学会等19世纪学术机构出版物
- 预处理流程:
- 使用NLTK进行句子切分
- 过滤短文本(<1000字符)和短句(<45字符)
技术实现
- 基础模型:GTE-small
- 微调策略:
- 采样1000对句子进行人工标注
- 使用余弦嵌入损失优化
- 索引系统:
- FAISS余弦相似度索引
- 多级阈值划分:
FAISS(Facebook AI Similarity Search)是Meta(原Facebook)开源的高效相似性搜索与向量聚类库,专为处理大规模高维数据设计。
实验结果
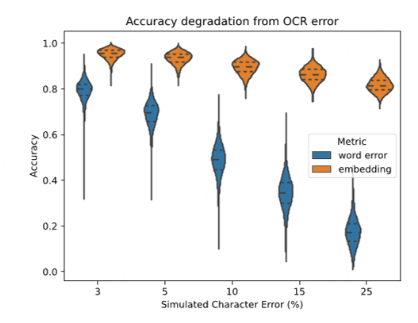
OCR鲁棒性验证
- 模拟实验设计:
- 原始文本:古腾堡计划人工转录本
- 误差注入:随机字符置换(0-20%错误率)
- 结论:
- 基于相似度的方法比基于词典的方法更具有鲁棒性
自然语言处理中的核心评估指标: CER=(S+D+I) N×100% (S: 替换字符数,D: 删除字符数,I: 插入字符数,N: 总字符数)
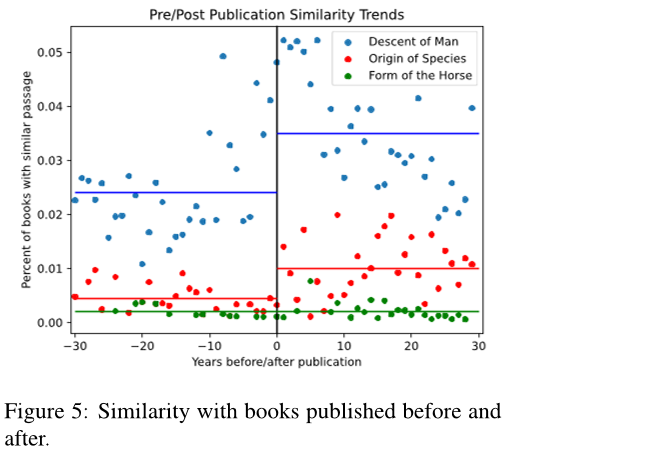
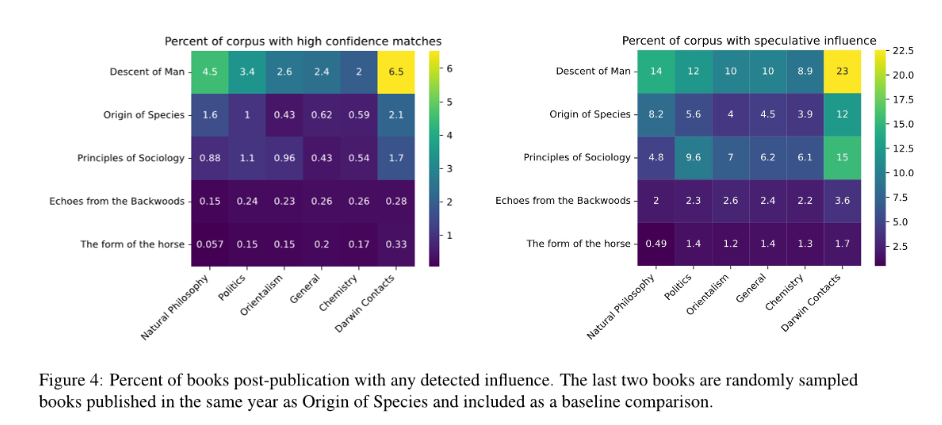
历史验证
- 实验设计
- 实验组:达尔文《物种起源》(1859)、《人类的由来》(1871)
- 对照组:随机选取同时期(1859年)的非相关书籍
- 验证逻辑
- 时间验证:著作发表前后的影响对比
- 预期结果:达尔文著作应对后期文本产生显著影响
- 学科验证:不同学科间的相似性差异
- 预期结果:生物学/地质学文本相似度 > 化学/政治学
- 人物验证:达尔文通信对象著作的关联强度
- 预期结果:通信密切者文本相似度更高
- 时间验证:著作发表前后的影响对比
结果
局限
1. 当前方法的局限性
- 语义相似性为主:GTE模型擅长捕捉特定主张的传播和影响,主要依赖语义相似性计算嵌入向量。
- 薄弱环节:在隐喻识别、文体相似性分析、论证结构与逻辑构建的影响分析上表现较弱。
2. 未来改进方向
- 结构化图嵌入方法:
- 计划通过生成AMR图(抽象意义表示)或知识图谱(如Opitz et al., 2021)解析单个论证的结构。
- 结合图神经网络(如Wang et al., 2018)生成图嵌入,以捕捉论证的深层结构信息,弥补现有模型对逻辑和结构分析的不足。
AMR图(抽象语义表示)是一种用图形简化句子深层含义的方法。它把句子中的核心概念(如人物、动作)变成节点,用箭头表示它们之间的关系(如“谁做了什么”),忽略语法细节(如时态、介词),专注于逻辑结构。例如,“医生治疗病人”会简化为“治疗”连接“医生”和“病人”。
3. 假阳性(False Positives)问题
- 问题来源:通用句或模板句(如过渡句、论证路标)因高频出现导致误判为相似主张。
- 解决方案:
- 过滤高频句子:从语料库中移除高频出现的非实质内容。
- 训练BERT分类器:通过监督学习识别并过滤这些非实质的“模板句”。
4. 假阴性(False Negatives)的挑战
- 不可评估性:完全消除假阴性需全语料标注,实际不可行。
- 初步验证:现有方法的结果与历史研究预期大致吻合,表明假阳/阴性比例相对平衡。
- 局限性:模型无法全面识别所有影响,但能发现新的潜在研究线索,需结合人工研究验证。
总结 (deepseek)
1. 数据预处理
- 语料清洗:移除过短文本(字符数 <1000)和无效句子(长度 <45字符),过滤目录、索引等非内容文本。
- 句子分割:使用NLTK工具对每本书进行句子级切分,保留完整的语义单元。
2. 模型选择与微调
- 基础模型:采用GTE-small(基于BERT的轻量级句子嵌入模型),因其在语义捕捉与计算效率上的平衡。
- 微调策略:
- 人工标注对比对:随机抽取1000对句子,人工标注三类情况:
- -1:偶然相似(如过渡句“综上所述”)。
- 1:语义相似但模型未捕获(需强化学习)。
- 0:正确匹配(保留原分数)。
- 损失函数:使用余弦嵌入损失(Cosine Embedding Loss)优化模型,提升对语义相似性的敏感度,抑制误报。
- 人工标注对比对:随机抽取1000对句子,人工标注三类情况:
3. 向量化与索引构建
- 句子嵌入生成:用微调后的GTE-small模型将每个句子编码为768维向量。
- 快速检索索引:基于FAISS库构建余弦相似度索引,支持高效近邻搜索(如Top-K相似句检索)。
4. 相似性搜索与阈值设定
- 多级置信阈值:
- >0.95:高置信(直接引用/高度相似)。
- >0.90:中等置信(转述/间接影响)。
- >0.85:低置信(隐喻/潜在关联)。
5. 抗OCR噪声的关键设计
- 子词分词(Subword Tokenization):BERT类模型将单词拆解为子词(如“unraveling”→“un-##ravel-##ing”),即使部分字符错误,仍能通过剩余子词捕捉语义。
- 语义主导的相似度计算:模型关注整体语义而非字符级匹配,对局部OCR错误(如“larvs”→“larvae”)不敏感。
与传统方法的对比优势
| 维度 | 传统方法(文本重用/主题模型) | 本文方法(句子嵌入) |
|---|---|---|
| 噪声鲁棒性 | 依赖字符/词匹配,OCR错误影响大 | 子词分词+语义编码,抗噪性强 |
| 语义捕捉 | 仅限字面匹配或主题分布 | 支持转述、隐喻、跨领域概念关联 |
| 计算效率 | 需复杂对齐(如n-gram比对),耗时 | FAISS索引实现秒级大规模检索 |
| 解释性 | 依赖高频词/主题标签,解释局限 | 可结合相似句对进行细粒度人工验证 |