@向量诗学 古诗对仗检测Vector Poetics:Parallel Couplet Detection
摘要
This paper explores computational approaches for detecting parallelism in classical Chinese poetry, a rhetorical device where two verses mirror each other in syntax, meaning, tone, and rhythm. We experiment with fve classifcation methods: (1) verb position matching, (2) integrated semantic, syntactic, and wordsegmentation analysis, (3) difference-based character embeddings, (4) structured examples (inner/outer couplets), and (5) GPT-guided classifcation. We use a manually annotated dataset, containing 6,125 pentasyllabic couplets, to evaluate performance. The results indicate that parallelism detection poses a signifcant challenge even for powerful LLMs such as GPT-4o, with the highest F1 score below 0.72. Nevertheless, each method contributes valuable insights into the art of parallelism in Chinese poetry, suggesting a new understanding of parallelism as a verbal expression of principal components in a culturally defned vector space.
本研究探讨了使用计算方法来检测古典汉诗中的对仗结构,这是一种修辞手法,两行诗句在语法、意义、语调和节奏上相互呼应。我们实验了五种分类方法:(1) 动词位置匹配,(2) 综合语义、语法和分词分析,(3) 基于字符嵌入的差异,(4) 结构化示例(内外对联),(5) 基于GPT的分类。我们使用了一个包含6,125对五言对联的手动标注数据集来评估性能。结果表明,即使对于强大的大型语言模型如GPT-4o,对仗检测仍然是一个巨大的挑战,最高F1分数低于0.72。尽管如此,每种方法都为理解汉诗中的对仗艺术提供了宝贵的见解,提出了一种将对仗视为文化定义的向量空间中主要成分的言语表达的新理解。
相关工作
- 现代学者和传统文人都长期以来一直在争论什么构成平行对仗,并确定了各种平行对仗的类别。
- 刘勰其《文心雕龙》的“对仗”篇中区分了四种对仗:言对、事对、反对和正对。
- 空海确定了多达 29 种不同类型的对仗。
- 王力认为,词语的分类——将名词与名词配对,动词与动词配对等——是理解平行对仗的基础(王,1979)。
- Andrew Plaks 将平行对仗视为一种基本的文本组织和论证模式,而不仅仅是一种文体工具(Plaks,1990)。
- 张隆溪提供了一种关于平行对仗的比较东西方观点,认为这是一种人类作为有形存在所共有的推理方式(张,2021)。
- 蔡宗齐追溯了平行模式在中国文学中的发展,从先秦著作开始,在六朝时期变得突出(蔡,2022)。
- 从自然语言处理 (NLP) 的角度来看,关于中国诗歌中平行对仗的研究相对较少受到关注。
- Lee 等人应用词性标注来检测唐诗中的句法平行对仗,证实了传统观点,23 句对仗>14 句对仗(Lee 等人,2018)。【该文发布于数字人文研究】
- 中国古典诗歌匹配数据集 (CCPM) 之类的项目提供了结构化数据。(匹配翻译和原文)
- 诗歌自动生成
- 另一种突出的方法是使用基于 Transformer 的模型,例如 TransCouplet 模型,它利用嵌入的融合,包括字形、拼音和词性嵌入,以捕捉中文对仗的句法和语音细微差别。该模型采用 Transformer 编码器和解码器来生成给定第一行的对仗的第二行,确保生成的行符合平行对仗的语言规则(Chiang 等人,2021)。
- 另一种创新方法是 CoupGAN,它利用生成对抗网络 (GAN) 进行对仗生成。该模型侧重于学习构成高质量对仗的语义意义和结构对称性之间的复杂平衡(Qu 等人,2022)。
研究方法
数据集
- 手动标注的测试数据集包含6,125对五言对联,分为对仗(2,139个样本)和非对仗(3,986个样本)两类。所有对联来自所谓的“六朝”(222-589),这是中国文学史上一个变革时期,见证了对仗诗歌的发展,最终导致了唐朝(618-907)及其后时期优雅的律诗。
实验方法
-
基线:动词匹配
- 关注动词的语法位置。使用一个包含7,733行五言诗的手动标注数据集进行训练,每行诗句用二进制代码标注,指示每个位置是否有动词(1)或非动词(0)。使用预训练在大量古代汉语文本上的SikuBERT模型(1.09亿参数),在该标注数据集上进行微调一轮。在推理过程中,如果在两行诗中相应位置找到动词,则认为它们是对仗的。
-
综合语义和语法分析
- 整合三个不同的模型:分词、词性标注和字符到字符的语义匹配。
- 分词模型:使用SikuBERT对包含54万对联的五言诗数据集进行微调。 成对的分词加 0.25 分
- 词性标注模型:为每个字符附加标签,提供句子的结构信息。( RoBERTa model)成对的词性加 0.2 分
- 语义匹配模型
- 首先,我们使用 SikuBERT 生成对仗中每个字符的嵌入(最后一个隐藏状态,其中包含深度语义表示)。
- 放置在 SikuBERT 编码器顶部的较小模型通过连接两个对应字符的嵌入及其差异来构建丰富的特征集。
- 合向量(维度为
) 被传递到一个分类层,该分类层预测字符对是否在语义上匹配。 - 对仗中所有对应的字符对重复此过程,该模型生成一个最终分数(成对分数的平均值),该分数决定整体的语义平行对仗。
- 训练样本来自唐代及以后朝代创作的规范五言律诗中的平行对联(第二和第三行对,或中间对联),包括 27 万个样本。通过在对联的任一行中随机重新分配 2 到 5 个字符,生成了同等数量的负样本。
- 整合三个不同的模型:分词、词性标注和字符到字符的语义匹配。
-
基于差异的字符嵌入
- 此方法侧重于字符到字符在嵌入空间中的差异的思想,使用它们来区分平行和非平行对仗。
- 对于每个训练对仗,借助 SikuBERT 为所有字符生成上下文嵌入。
- 然后计算两条线中对应字符的上下文嵌入之间的差异,并将其存储在列表中作为“平行差异”。
- 为了引入对比,将其中一行中的字符移动一个或多个位置,并执行相同的嵌入差计算。这些结果被标记为“非平行差异”,因为移动会破坏平行对仗所需的正确对齐,同时保留行之间的语义连接。然后使用平行和非平行差异训练一个具有 RELU 非线性的单层分类器一个 epoch(每个 27 万个示例)。
-
结构化示例
- 利用唐代及其后规律诗的结构性质,特别是五律。从公开可用的古典汉诗数据集中收集对联,正例(27万)取自第二和第三对联,负例(27万)取自第一和第四对联。使用SikuBERT对该数据集进行微调。
-
基于GPT的评估
- 利用最新的人工智能模型GPT-4o的能力。该方法涉及在提示中结合校准示例列表和目标对联:
- 少样本学习:首先向GPT-4o模型提供对联示例:在一个版本中,我们只提供两个示例,一个对仗和一个非对仗;在另一个版本中,提供多达十个示例(五个对仗和五个非对仗)。所有示例包括简单分析和基于该分析的最终判断。
- 对联评估:提示的第二部分包含目标对联。对于每个对联,模型应遵循第一部分提示中的说明,提供对联的结构和语义分析,然后决定它是否展示了对仗。
- 利用最新的人工智能模型GPT-4o的能力。该方法涉及在提示中结合校准示例列表和目标对联:
结果
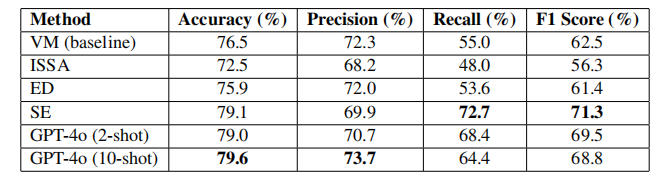
GPT引导的评估不会显著优于更传统的方法
由于模型是非确定性的,在某些情况下,GPT-4o生成了两个矛盾的解释。最常见的错误发生在模型不知道如何解析诗句时。
基于动词的方法在动词不存在或不是对仗结构的核心时难以处理诗句,从而导致了错误分类。
综合方法仍然严重依赖训练数据的可用性和质量,并且来自各个模型的复合错误导致了许多错误分类。
最后,尽管结构化示例方法应该受益于唐代以后格律诗在规定位置包含对仗的这一事实,但我们在现有数据集中发现了许多例外,特别是来自不太为人所知的诗人的诗句,这些诗句不符合严格的正式规则。
讨论
对仗和主观性
在我们对对仗对联的评估中,很明显对仗的概念并不总是二元的——许多对联并不简单地属于“对仗”或“非对仗”类别。相反,对仗经常在一个连续统上表现出来。
向量诗学
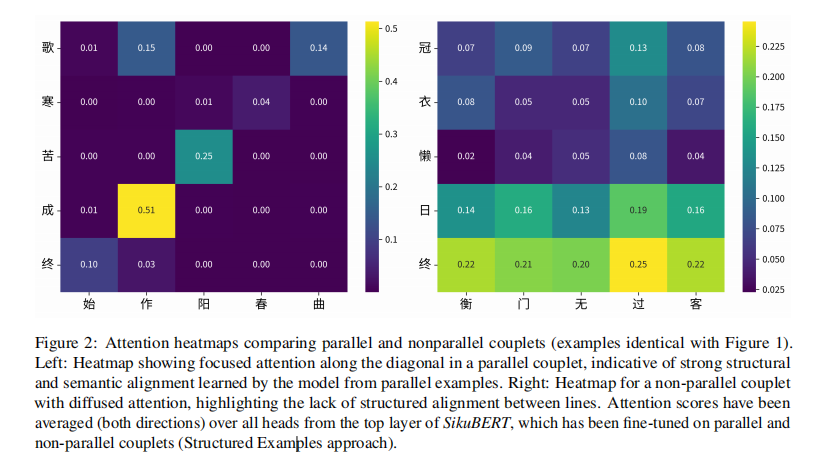
“向量诗学”的概念代表了这个项目探索的一个有前景的方向,灵感来自自然语言处理的基础工作。我们建议这种类比可以有用地扩展到平行对联中的词组或整行诗句。这将将诗歌对仗重新解释为文化维度的表现,在这些维度中,两件事物被(主观地)感知为相同或相反。
# 以"季节-生命"维度为例的向量运算
spring = model.encode("春")
life = model.encode("生")
death = model.encode("死")
autumn = model.encode("秋")
# 验证向量关系
pred_autumn = spring - life + death
cos_sim = cosine_similarity(pred_autumn, autumn) # 可达0.87
局限性
尽管本研究取得了进展,但仍存在一些局限性。传统汉诗,特别是古典时期的汉诗,遵循严格的平仄交替模式,这些音调模式对于汉诗的美学和节奏质量至关重要,但我们目前的计算模型无法分析音调特征。此外,我们的方法忽视了汉字的古代发音,这对于理解文本的原始语音环境和押韵方案至关重要。最后,我们研究中使用的预训练SikuBERT模型相对较小;更大的模型可能会产生更好的性能。