@庞仙等:《融合多源提示信息的新词语释义自动生成》
主要是关于提示词的撰写——黑话“融合多源提示信息”。可多借鉴对比实验的设计,怎么把(似乎)一件小事说长,说科学,量化评估。
摘要
- 研究目的:提出基于大语言模型(LLM)的新词语释义自动生成方法,通过提示学习融合多源信息提升生成效果。
- 方法:结合上下文语境、类型信息和示例信息构建提示模板,使用ChatGPT(GPT-3.5)和文心一言(ERNIE-Bot)生成释义。
- 实验结果:
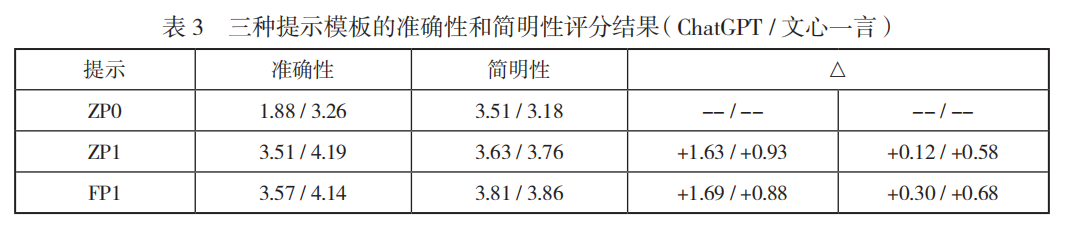
- 零样本(Zero-shot)下,融合多源信息的提示模板(ZP1)显著提升准确性(ChatGPT:1.88→3.51;文心一言:3.26→4.19)。
- 少样本(Few-shot)引入相似示例后,效果提升有限(ChatGPT +0.06,文心一言 -0.05)。
- 新造词和简略词生成效果最佳,外来词最差。
- 结论:该方法可为词典编纂提供高效辅助工具,需人工微调即可应用。
引言
- 背景:
- 新词语随社会发展快速涌现,传统人工释义效率低、主观性强。
- 自动化生成面临释义复杂性与动态性、信息分散性等挑战。
- 研究路线:
- 微调专用模型(需标注数据)。
- 利用LLM的零样本/少样本能力,通过提示学习生成释义。
相关研究
- 已有工作:
- 基于神经网络的序列到序列模型(如双编码器、BERT融合上下文)。
- 引入额外信息(如HowNet义原、词素分解)。
- 本文创新:
- 首次将提示学习与大语言模型结合,专门解决新词语释义生成问题。
方法
新词语数据集
- 数据构成:
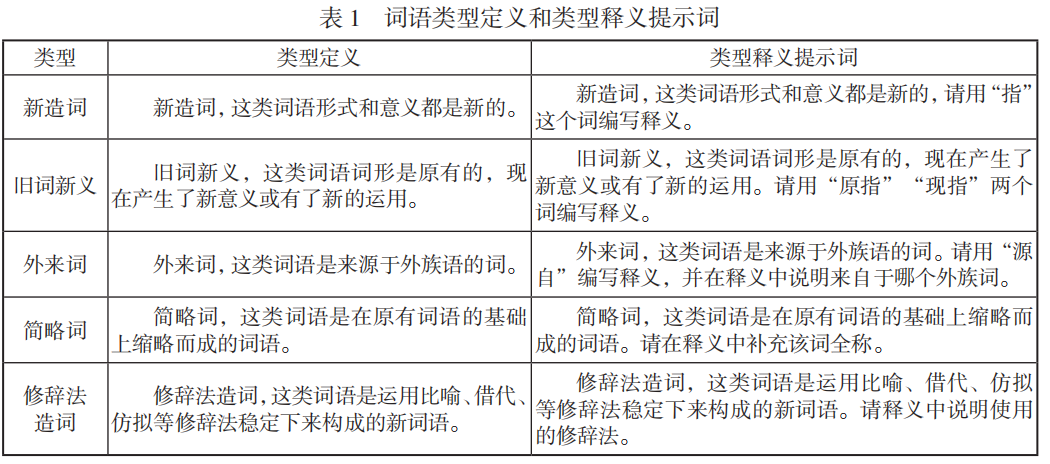
- 40个新词语,5类(新造词、旧词新义、外来词、简略词、修辞法造词)。
- 每词含2个例句、类型信息,部分提供相似示例(共11个)。
- 类型定义与提示词
提示学习框架
- 核心要素:
- 上下文语境(例句)。
- 类型信息(定义与提示词)。
- 示例信息(相似案例)。
- 模板设计:
- ZP0(基础):仅词语。
- ZP1(多源融合):词语+例句+类型提示词。
- FP1(少样本):ZP1 + 相似示例。

实验结果
主要结果
- 人工评估指标:准确性(1-5分)、简明性(1-5分)。
- 示例生成对比(“闭环泡泡”):
- ZP0生成偏字面解释,ZP1正确关联“疫情防控闭环管理”。
- ZP0生成偏字面解释,ZP1正确关联“疫情防控闭环管理”。
对比实验
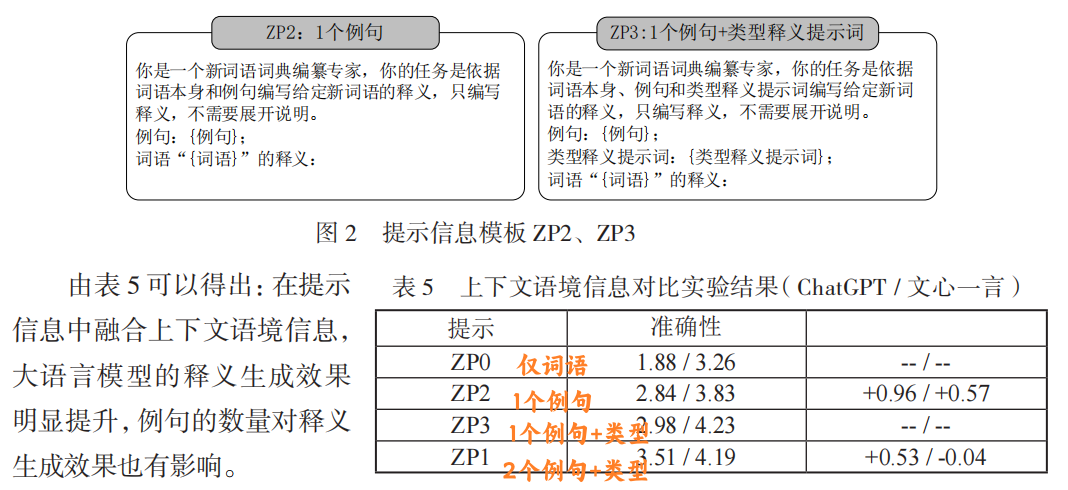
上下文语境影响:
- 例句数量增加提升准确性,但过多可能引入噪声。
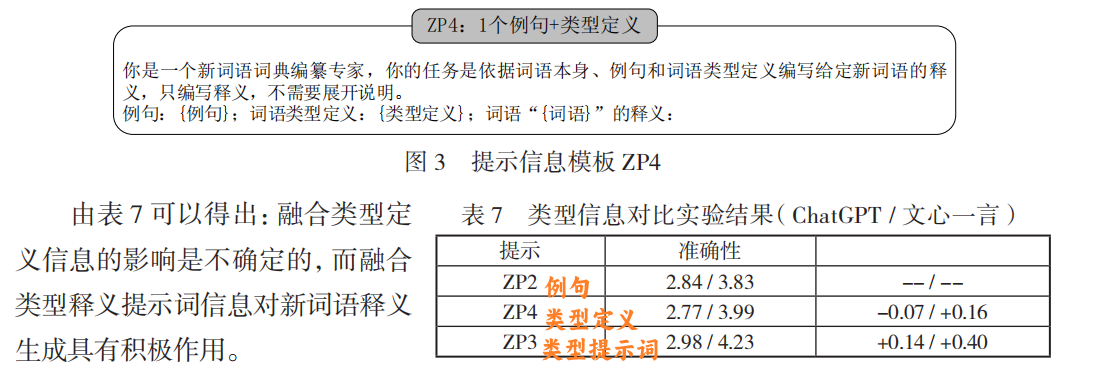
类型信息作用:
- 类型提示词(如“旧词新义:原指…现指…”)比类型定义更有效。
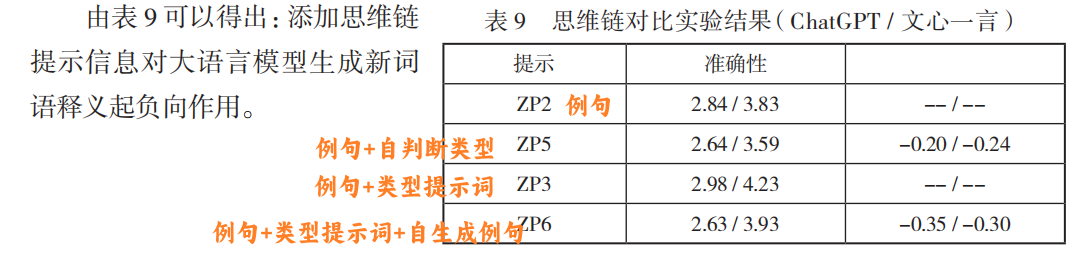
思维链负向影响:
- 模型自主判别类型或生成例句会引入错误(如误判“润”为旧词新义)。
Bug🐞
-
实验设计问题:
- 论文中将“模型自生成类型/例句”与“人工提供准确类型/例句”直接对比,本质上是任务设定不匹配。前者要求模型同时完成“信息推断+释义生成”,后者仅需“释义生成”。
- 正确的对比应分为两步:
- 步骤1:评估模型自主推断类型/例句的准确性。
- 步骤2:在已知准确信息下,对比思维链与直接生成的效果。
-
可能的改进方向:
- 分离任务阶段:先验证模型能否正确推断类型/生成合理例句,再基于正确信息生成释义。
- 控制变量对比:在相同信息输入下(如人工提供类型+模型生成例句),评估思维链是否提升生成质量。
补充观点
论文中思维链的负向影响可能源于误差传播:模型若在前期步骤(如类型判断)出错,会导致后续释义生成偏离正确方向。
上下文学习(in-context learning)对释义生成的影响
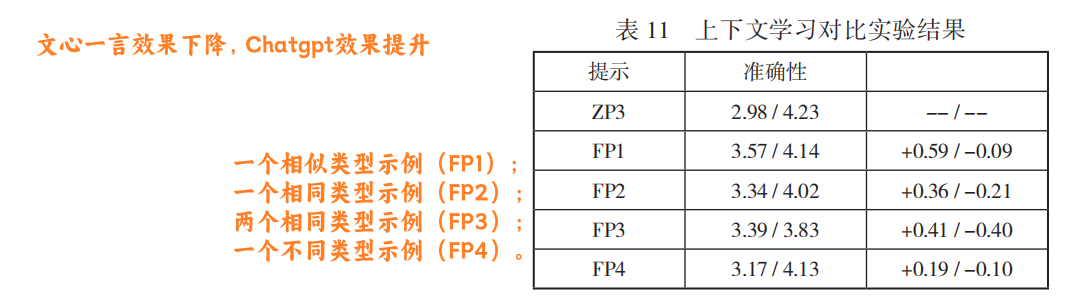
相似示例举例:反向抹零→反向背调
分析实验
- 提示信息的长度:提示词都在模型有效长度限制以内,所以不存在长度限制问题
- 新词语类型对释义生成的影响:不同类型的新词语的释义生成效果有明显差异,整体上,新造词和简略词的释义准确性最高,而外来词的释义准确性较低。
- 大语言模型对释义生成的影响:文心一言效果更准确,Chatgpt 对提示信息更敏感。
- 大语言模型生成释义的随机性实验:每个类型选一个词,用 zp 3 作为提示词,生成五个结果进行人工评估。结论是总体来说语义具有一致性。