@张逸勤《基于生成式大语言模型的非遗文本嵌套命名实体识别研究》
摘要
摘 要:
[目的/意义] 本研究探索生成式大语言模型在非物质文化遗产文本嵌套命名实体识别中的应用,以提高特定领域复杂文本中多层次实体的识别精度。
[方法/过程] 研究对比了 GPT-4、Claude 3.5Sonnet、ChatGLM2-6b 等多种生成式大语言模型与 BERT+GlobalPointer 基线模型的性能,并设计了思维链与行为推理模式两种提示工程技术以优化模型复杂上下文中的识别能力。
[结果/结论] GPT-4 模型采用行为推理模式时表现最佳,Qwen2-72B 模型达到 91.16%的最高 F1 值,展现出优异的领域适应性。研究验证了生成式大语言模型在非遗文本嵌套实体识别中的应用潜力,然而在处理长文本和复杂嵌套结构时仍存在计算资源需求高、推理速度慢等挑战。未来研究将通过混合模型或多任务学习框架,融合 BERT 模型的稳定性与生成式大语言模型的灵活性以提升识别性能。
1 引言
- 非遗的重要性与数字化保护
非物质文化遗产承载着文化意义,其数字化保护是当前研究重点。 - NER 的作用与挑战
命名实体识别(NER)现有研究主要集中在一般领域的实体识别,对于非遗领域的嵌套实体识别研究较少。 - 嵌套实体识别(Nested NER)是命名实体识别(NER)的一种高级形式,旨在识别文本中层次结构复杂的实体。
- 先有模型在处理非遗领域非结构化文本中的嵌套实体识别问题时,这些方法往往难以应对复杂的嵌套结构,导致信息丢失和错误识别,进而降低识别的准确率
- 研究目标
本研究基于生成式语言模型,提出了一种针对非遗文本的嵌套命名实体识别方法,通过优化模型结构和训练方法以提高非遗文本嵌套实体识别的准确性和鲁棒性。
本文的主要贡献在于:
①探究一种基于生成式大语言模型的有效识别嵌套实体的新方法:利用生成式大语言模型的强大语义理解能力,有效处理复杂的嵌套命名实体识别问题,显著提高了识别的准确性和鲁棒性;
②提示工程设计了思维链(Chain of Thought,CoT)与行为推理模式(Reason-Act,ReAct):引入思维链(CoT)和行为推理模式(ReAct),通过逐步推理和行动反馈,增强模型在复杂上下文中的决策能力,使得识别结果更为精确;
③在非物质文化遗产文本数据集上进行实验评估:本文验证了生成式大语言模型应用于非遗文本嵌套实体识别任务的可行性,通过在非遗领域语料库上进行实证研究,验证了模型的优越性能,展示了其在实际应用中的潜力。
2 相关工作
近年来,国内学者针对非遗文本的实体识别问题开展了一系列研究,并取得了一定成果。在方法层面,研究主要集中于深度学习模型的应用:
- 迁移学习:如汪琳等针对非遗陶瓷工艺领域,提出融合迁移学习的方法,实现特定领域新词发现。
- 机器阅读理解:范涛等将机器阅读理解技术引入实体抽取,构建ICHQA模型,提升任务准确率。
- BERT模型:刘浏等基于BERT构建实体识别框架,为传统音乐非遗术语知识库建设提供支持。
在知识组织层面,范青等运用RDF三元组描述框架,系统化实现非遗知识的识别、抽取与表示,为区域性非遗知识库建设奠定基础。
现有挑战
尽管取得上述进展,现有研究多聚焦于单层实体识别和简单关系抽取,在处理非遗文本特有的嵌套实体结构时仍面临困难。传统深度学习方法难以有效捕捉实体间的层次关系,导致在复杂文本中出现信息损失和识别偏差。
3 方法
- 模型选择
- 包括GPT-4、Claude3.5Sonnet、chatglm2-6b等生成式大语言模型并通过不同的提示工程策略来优化识别效果。
- 文中介绍了不同的大模型,这里省略
- 选择以BERT为基础架构并融合GlobalPointer方法的预训练语言模型作为基线模型
- 在BERT模型的基础上,SuJ L等引入了一种乘法注意力机制,构建了新颖的基于跨度的命名实体识别(NER)框架,称为GlobalPointer(GP)
- 其创新在于设计了一种新型分类损失函数,通过对少见实体类别进行加权,显著减少了类别不平衡问题,提高了整体分类性能。
- 包括GPT-4、Claude3.5Sonnet、chatglm2-6b等生成式大语言模型并通过不同的提示工程策略来优化识别效果。
4 实验
- 实验设置
- 数据集:通过爬虫技术获取第1~5批国家级非物质文化遗产代表性项目名录,共计1557个国家级项目及3610个子项。最终构建了包含21485行的语料集。双人交叉标注。
- 评价指标:精确率(𝑃𝑟𝑒𝑐𝑖𝑠𝑖𝑜𝑛)、召回率(𝑅𝑒𝑐𝑎𝑙𝑙)和F1值。
- 提示工程
- 思维链 Chain of Thought, CoT
- 行为推理模式 Reason-Act, ReAct
5 结果与讨论
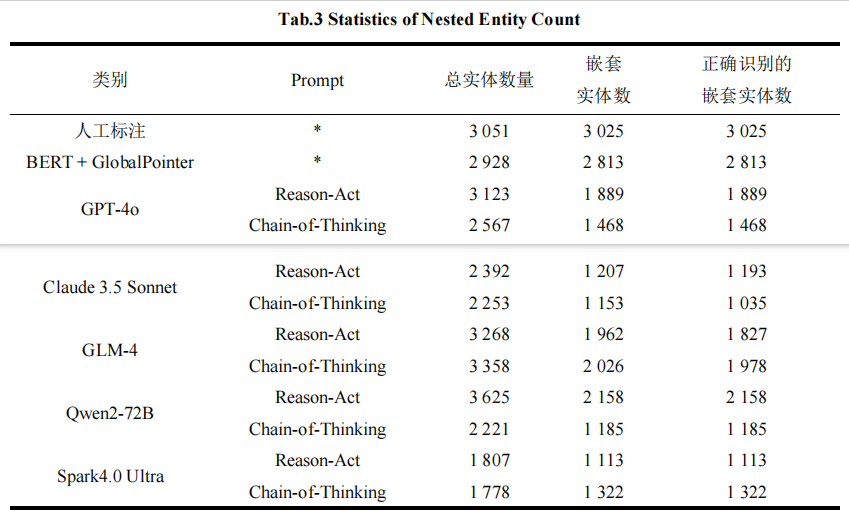
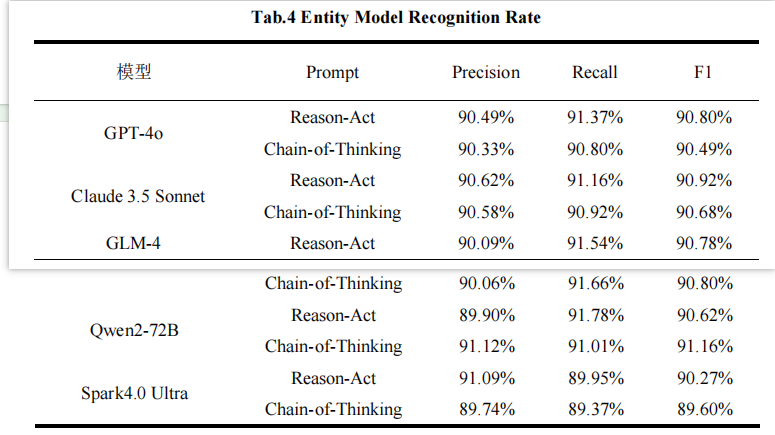
实验结果
- GPT-4表现最为突出,使用Reason-Act方法识别出3123个实体,虽然嵌套实体数量(1889个)低于人工标注,但仍显著高于其他模型。
- 大型语言模型在处理复杂非物质文化遗产文本嵌套实体识别任务时具有显著优势,能够有效捕捉文本中的上下文关联关系和复杂的实体嵌套结构。
- 错误类型主要分为四类:边界识别错误(43.2%)、类型判断错误(31.5%)、嵌套关系错误(18.7%)和其他错误(6.6%)。
- 大语言模型在处理文化底蕴深厚的复杂文本时对实体边界的标注精确性明显低于普通实体。这反映出其对非遗领域特定语境的理解深度的不足以及对多层次语义结构的建模能力仍然有待提升。
结果讨论
数据需求与迁移能力
- BERT模型在特定领域任务(如非遗、生物医药等)的表现依赖大规模高质量训练数据,需进行领域微调
- 生成式大语言模型通过指令微调和提示工程实现零样本/低数据标注,利用通用语料库展现更强领域适应性和迁移能力
领域适应性
- GLM-4模型使用"Chain-of-Thinking"提示策略识别了3,358个总实体(正确1,978个嵌套实体),优于"Reason-Act"提示
- 非遗领域通过逐步推理引导,显著提升文化术语和嵌套结构识别能力
- 领域适应需结合预训练范式与任务特征提示策略设计
模型稳定性与结果一致性
- BERT凭借双向编码架构和领域微调→在结构化任务处理中展现出显著的稳定性优势。
- 生成式大语言模型存在输出波动,需精细控制temperature参数降低随机性
- 生成式模型需更严格质量控制机制才能达到BERT的稳定性水平