@李炜等:《针对古代经典文献的引用查找问题的数据构建与匹配方法》
总结📔
还是挺详细的,我大概看懂了的。三种方法,以及三种方法的融合方法。然后做实验。这提供给我们一个思路就是去想机器学习可以解决哪些真实的人文学者的问题。
摘要
- 研究背景与意义:
- 传统文献引用定位耗时
- 自动检测技术对数字人文领域发展具有重要价值
- 方法创新:
- 提出多种无监督基线方法
- 构建宋代二程儒家经典引用标注数据集
- 实验结果:
- 集成方法取得句子级检测ROC-AUC 87.83%
- 段落级检测ROC-AUC 91.02%
引言
- 传统的基于字符匹配的方法存在依赖专家经验、灵活度不足、覆盖范围不全、难以准确把握上下文语义内涵等问题
- 预训练模型: 基于对比学习提出的SIMCSE在预训练语言模型的基础上, 通过对句中字符表示随机加入Dropout噪声的方式来获得对比学习中的正例, 因而能够通过自监督方式学习到包含语义信息的更有区分度的向量表示。 #待读文献
- 相关工作
- 黄水清等人和周好等人针对规整古代文献中出现的论著名(明引)采用基于序列标注的方法进行了识别和统计学分析。
- 尽管该方法可以识别带有明确书名的相关表述,后世文献(如宋代及之后)对早期经典文献的引用大多只引用早期经典的只言片语,并且是基于语义的引用,因此该方法并不适用于广泛存在于后世文献中对早期经典文献的引用识别(暗引)。
- 耿云冬……用 siku-bert 完成了自然语言处理的一些传统任务(词性标注……),与直接的人文领域研究有一定举例
- 黄水清等人和周好等人针对规整古代文献中出现的论著名(明引)采用基于序列标注的方法进行了识别和统计学分析。
2 数据集构建
2.1 数据来源
- 选取《二程集》作为研究对象。中华书局 2004 版。
- 十三经文本数据来源于 ctext. org 网站。
- 停用词集构建
方法
3.1 结合专家知识的规则方法
-
匹配规则:
-
特征处理:
- 支持4种gram组合检测,如果有重复片段只考虑最长的
- 引入停用词惩罚机制
- 只要最后的 score 大于 1,就判断引用关系成立
3.2 基于预训练语言模型的字符片段语义匹配方法
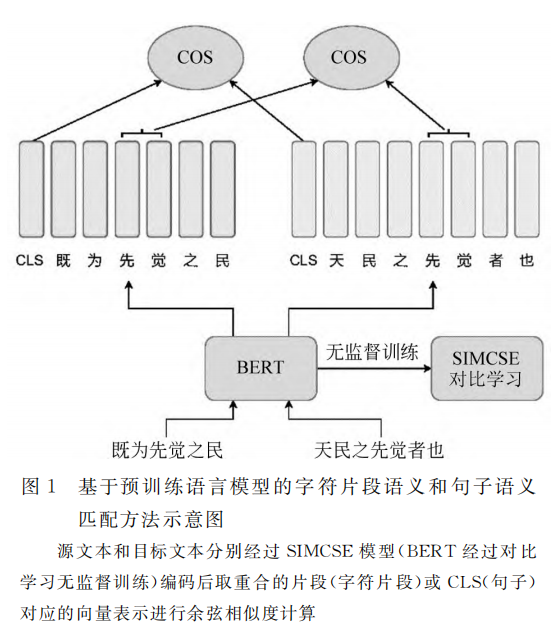
-
模型架构:
- 基于SikuBERT预训练模型
- 采用对比学习框架 在源文本和目标文本集上均采用掩码语言模型 (Masked Language Model, MLM) 目 标 和 SIMCSE中的对比学习目标进行适应性训练, 来学习得到更贴合研究对象文本的模型参数。
-
特征计算:
M-k-1:m 为目标文本的长度。目标文本 k 元组数量。用于规范化
3.3 基于预训练语言模型的句子语义匹配方法
3.4 复合判断方法
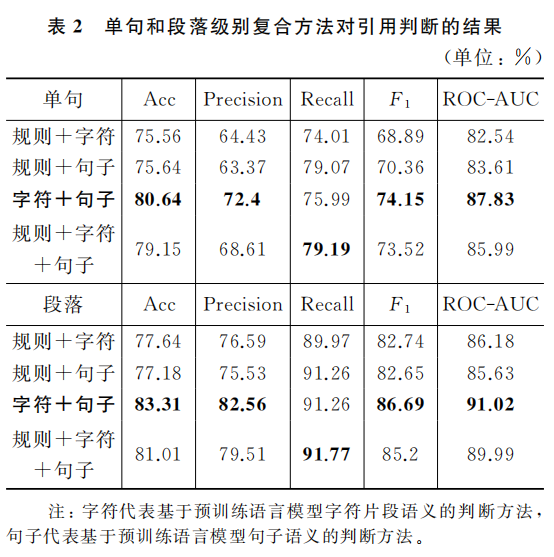
四种复合模型:规则+字符,规则+句子,字符+句子,规则+字符+句子。
复合判断方法=三种方法加权平均
实验
4.1 实验设置
-
基础模型:
- SikuBERT-base(768维度,12层Transformer)
-
评价指标:
ROC-AUC(Receiver Operating Characteristic - Area Under Curve)是评估二分类模型性能的核心指标,用于衡量模型在不同分类阈值下区分正负类别的能力。
- ROC曲线:以真阳性率(TPR,即召回率)为纵轴,假阳性率(FPR)为横轴绘制而成。TPR表示正确识别正例的比例(TPR = TP / (TP + FN)),FPR表示错误将负例判为正例的比例(FPR = FP / (FP + TN))。
- AUC值:ROC曲线下的面积,取值范围为0到1。AUC=1表示模型完美区分正负类;AUC=0.5表示模型与随机猜测无异;AUC<0.5则说明模型存在严重问题。
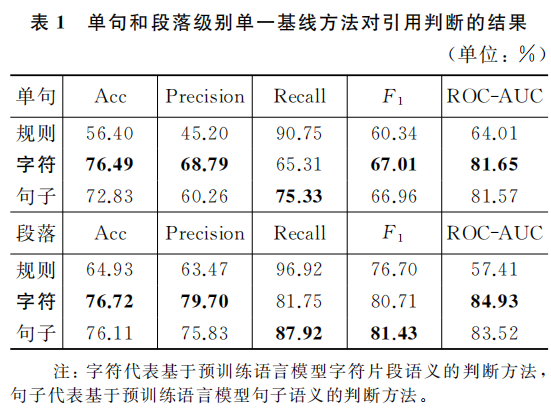
4.4 实验结果
4.5 实验分析
使用对比学习目标的效果
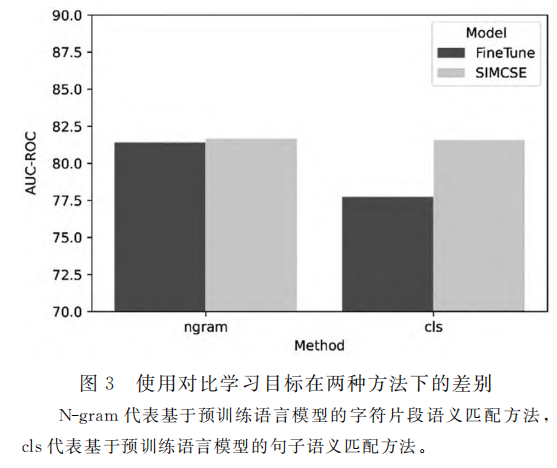
加入对比学习目标后,相比于只做掩码语言模型训练,提升主要体现在句子级别的语义提升上,而在字符片段级别的语义上基本没有改变,这是因为SIMCSE中的对比学习目标主要针对的是整句文本表示的学习,而对字符级别影响不大。
使用停用词的效果
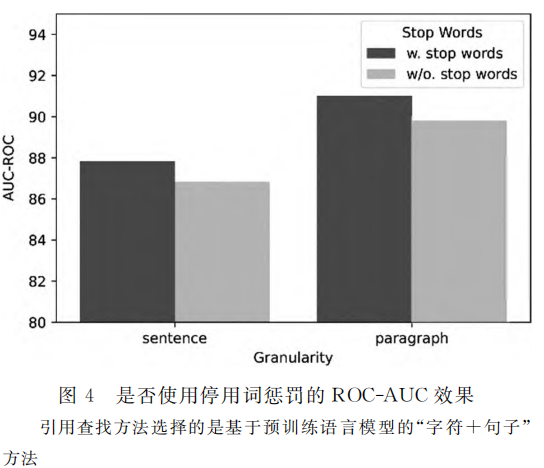
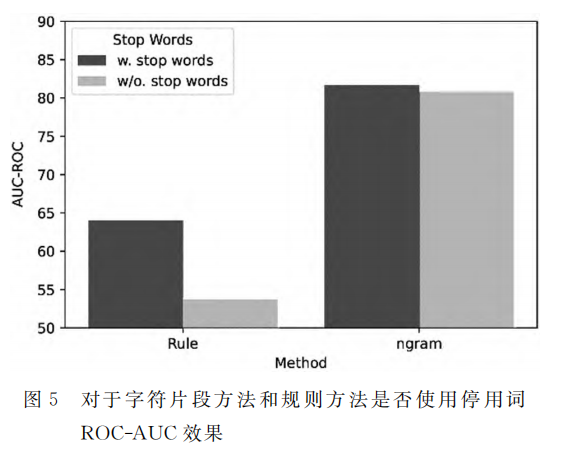
w/o. = without 的缩写