@汪梦翔:《基于多信息资源的汉语复合词自动生成研究》
总结💡
试图通过模型找到近义词,也组配一些新词。在方法上的创新是融合了多种信息构成了一套完整的工作流程,但似乎有些细节没有很详细。读完尚有一些疑问,比如说平行周遍法则判断的算法是如何实现的/语素组配规则的具体判断方式等等。另外对于新词自动生成的研究意义不是很理解。
1. 研究背景与目标
- 探讨基于多信息资源的汉语复合词自动生成方法。
- 目标:
- 生成已有的近义词。
- 生成未登录的新词。
- 两类结果均涉及语素的替换。
2. 方法
- 从语素层面入手,依据语言学中的平行周遍规则,界定可替换语素的取值范围。
- 构建基于多信息资源的MIFSSM模型(多信息融合语义相似度模型)。
- 结合语素词典的释义文本与HowNet中语素间关系的知识。
- 生成具有语义近似序列且能区分不同义项的近义语素集。
- 选用适当的组配规则对替换后的语素进行新的组合。
- 利用ChatGPT进行人机互动式评估。
3. 核心问题
- 语义解构:对汉语词汇的深层语义理解和分析。
- 语素替换:对汉语词语的扩展,使同一个词可以有无限种生成的可能。
- 搭配规则:对新生成的语义元素进行限制和规范,确保新的语义成分不能随意搭配和生成。
- 语义解构是基础,语素替换是目标,搭配规则是关键。
4. 相关研究
- 词语自动生成技术
- 以抽取式方法为主,集中在文本摘要领域。
- 语义向量模型
- Mikolov等(2013)的Word2vec。
- Tissier等(2017)的Dict2vec模型。 #待读文献
- 深度学习模型:
- Bert和GPT模型。
- 汉语词的自动生成研究:
- 汉语的特殊性:意合语言,词的自动生成与词义的分析与组配密切相关。
- 现有研究
- 苑春法等(1998)的“汉语语素数据库”。
- 亢世勇等(2004)的“汉字义类信息库”、“汉语语义构词信息库”。
- 董振东等(2007)的“知网(Hownet)”。
- 现有研究的缺陷
- 苑春法没有形成不同语素项之间的关联,无法满足语素义变换的计算性需求,也无法有效地为汉语词的自动生成服务。
- 亢世勇的语义类型划分较细,给计算机划分造成一定难度(cm:: 细了不能合并吗?疑惑,这也能叫缺点)
- 董振东的义原不是词也不是语素,缺少形式化的依托(Cm:: 不太具体)
- 近些年吸收了深度学习理念的研究:
- Zhang等(2014)使用RNN模型根据语素数据库中的关键词语义知识自动生成中国古诗。
- Yan等(2016)使用带有注意力机制的encoder-decoder模型在自有语义知识库前提下自动生成中文对联。
- 范齐楠等(2021)使用基于Bert和柱搜索技术的中文释义模型自动生成中文释义。
- 岂凡超等(2022)依托“多通道反向词典”模型而开发的“反向词典(Wantwords)”能根据释义或关键词自动生成相关词语。
5. 数据来源
- 董振东的HowNet(知网):揭示概念与概念之间以及概念所具有的属性之间的语义知识库。
- 本文利用了 HowNet 中 2000 多个义原关系,它们由 223767 个以中英文词和词组所代表的概念构成,HowNet 为每个概念标注了基于义原的定义、情感倾向、例句等信息,这里的每个概念我们可以理解为一个语素。
- 傅兴岭、陈章焕主编的《常用构词字典》。
- 收录4457个字头语素,近1.2万个义项。
- 实现了构词穷举,把常见的同一词根语素的汉语词集中在一起,标注了构词格式。
- “中文词汇网络知识库(CWN)”资源。
- 每个义项拥有多条例句 。

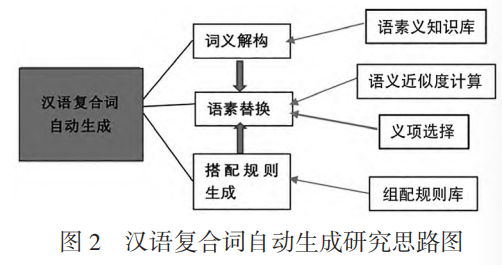
6. 自动生成流程
- 语义解构:依托经过优化的《常用构词字典》构建语素义知识库。
- 语素替换,方法详见下MIFSSM 模型:
- 确定关联语素的取值范围→平行周遍:
- 陈保亚(2006)提出的三个条件(平行特征、组合关系平行、分布平行)。
- 平行特征:替换的语素在语义、语法、或用法上具有一定的相似性。(替换的部分都是名词/动词……)
- 组合关系平行:在被替换部分保持平行特征的前提下,替换后的组合关系也应保持平行,即替换后的语素应能够与原组合中的其他语素形成合理的语义和语法关系(替换前后都构成动宾关系……)
- 分布平行:替换后的复合词需能够在相同的语境和语法结构中自然出现。
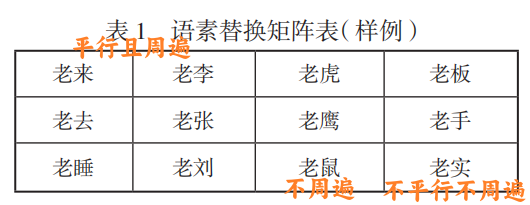
- 陈保亚(2006)提出的三个条件(平行特征、组合关系平行、分布平行)。
- 解决语素的筛选问题,确定该字用哪一个义项:
- 对每个具有不同义项的字进行编码的形式来确定具体的义项字(如“打1_25_18”,词典中打字的第一个条目,共有 25 个义项,取第 18 个义项)。
- 语素义的相似度计算:
- 构建高质量近义语素集,并根据语义近似度进行排序。
- 确定关联语素的取值范围→平行周遍:
- 搭配规则生成。
7. MIFSSM模型
- 融合多种信息的语义相似度模型。
- 步骤:
- 数据预处理(分词、去标点、文本组块化)。
- 释义文本的嵌入替换(将其他字典释义代入语素词典的释义模块)。
- 在《常用构词字典》(记为字典A)中,“捕”解释为“捉、逮”,而“捉”和“逮”在字典B中解释为:“使人或动物落入自己的手中”“特指经过追赶或试图抓”。经过释义信息的代入后,“捕”的解释可以表示为:“捉(使人或动物落入自己的手中)、逮(特指经过追赶或试图抓)”
- 获取知识图谱关系(利用HowNet中的关系和属性作为补充特征)。
- 生成综合的语素特征向量,计算语义相似度(计算多信息特征嵌入合成后的词向量和原语素向量的余弦值,来刻画不同语素之间的相似度并排序)。
- 调整近似度阈限值和语义向量维度值,选取最优近义语素集。
- 语义向量维度值设定为300,近似度阈限值为0.62。
8. 语素组配规则库
- 汉语词内部组配规则分为四种,并对汉语词内部的语义来源特征进行了编码。
- 示例:
| 组配规则类型 | 语义来源 | 例词 | 构词结构 |
|---|---|---|---|
| 00 | 和内部语素无关 | 沙发 | 单纯词 |
| 01 | 和后语素较多关联 | 老师 | 前附加 |
| 10 | 和前语素较多关联 | 纸张 | 名量、联合 |
| 11 | 前后语素义均较多关联 | 选材 | 述宾、定中 |
- 构词结构特征描述:主谓、定中、状中、述宾、数量等。
- 通过构建众包平台的方式依托现有语言学规则进行半监督标注,以确保组配规则的有效性。
9. 实验验证
- 计算两个语素词向量之间的余弦相似度来衡量它们之间的语义近似度。
- 利用Wordsim-297测试集中各词的相似度评分。
- Wordsim-297 是一个词向量数据集,是由对应的英文数据翻译成的中文数据,它提供了中文词汇 297 对以及人工标注的相似性分数,主要用于测试中文词向量模型的准确度和相关性。
- 对比基于维基百科语料的word2vec模型、基于自有词典语料的BERT模型、基于多信息资源的MIFSSM模型在不同窗口词下训练的结果。计算皮尔森相关系数 R 分。
- 与自动词语生成平台Wantwords进行比较。
- 随机抽取 100 个 关键词生成结果,取最相关 20 例,辅助 Chatgpt 人工评估。采用 liker 量表(五级符合不符合)
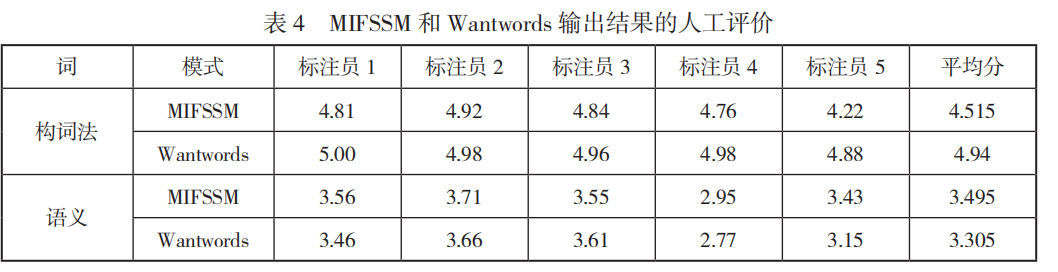
- Wantwords 基于词库,在构词法上得分较高,而MIFSSM 生成未登录的新词,会让人在搭配规则上产生犹豫判断。
- 在语义关联上相关度整体不高,是因为有的词关联本来就少,计算机会尽量凑够数量。Wantwords 略逊一筹。
- 选取“采取”和“法律”两个词进行复合词自动生成的结果检验。

10. 结论
- 本研究整合了词典释义、语素关系等多种信息资源,构建了MIFSSM预训练模型,生成高质量的近义语素集合,然后选择相应的平行周遍组配规则对替换的语素进行规约。
- 利用现有的人工智能工具ChatGPT,通过让其学习简单的打分规则,有效地辅助了人工评价过程。
- 实验结果显示,在小型训练集上,本研究在词语近似替换方面的表现略优于基于网络文本的word2vec和基于自有数据集的BERT模型。同时,与自动词语生成平台Wantwords相比,本研究在语义理解和新词生成方面展现出一定的优势。
- 局限性:语素义的近似集并未完全覆盖所有近似语素,导致人们容易联想到的某些近义词无法生成。
D 老师的全流程解析(有一些发挥)😁
Step 1:输入处理与语义解构
输入:用户输入目标词(如“高峰”)。
核心任务:将复合词拆解为语素项,并分析语义关系。
具体操作:
- 语素拆分:将“高峰”拆解为“高”+“峰”。
- 语义解析:
- 通过《常用构词字典》查询语素义:
- “高”:① 垂直距离大(形容词);② 等级在上(形容词)。
- “峰”:① 山的尖顶(名词)。
- 结合HowNet知识图谱确认语义关系:“高”修饰“峰”→ 定中结构(形容词+名词)。
- 通过《常用构词字典》查询语素义:
- 标记可替换位置:根据平行周遍规则,确定“峰”为可替换语素(名词性,地形类)。
Step 2:近义语素查找(MIFSSM模型工作流程)
目标:为“峰”生成近义语素候选集(如“岭”“顶”“峦”)。
模型运作流程:
4. 多源数据融合:
- 从《常用构词字典》提取“峰”的释义:“山的尖顶”。
- 从HowNet获取“峰”的语义属性:
{上位义原=地形, 特征=高位, 关联词=山、陡峭}。
- 语义向量生成:
- 将“峰”的释义文本(如“山的尖顶”)输入MIFSSM模型,生成300维语义向量。
- 同时融合HowNet中的义原关系(如“地形→高位”)。
- 相似度计算:
- 遍历所有名词性语素(如“岭”“顶”“沙”“石”)。
- 计算与“峰”的余弦相似度(公式:
)。 - 筛选相似度>0.62的语素:
- “岭”(0.78)、“顶”(0.75)、“峦”(0.68)→ 保留。
- “沙”(0.32)、“石”(0.41)→ 剔除。
输出候选集:{岭, 顶, 峦}。
Step 3:组配规则约束(动态过滤非法组合)
目标:确保替换后的语素组合符合汉语构词规律。
规则库匹配示例:
7. 结构约束:原词“高峰”为定中结构(形容词+名词),新词需保持相同结构。
- 合法组合:高+岭→“高岭”(定中结构,形容词+名词)。
- 非法示例:高+跑→“高跑”(违反名词性要求)。
- 语义约束:替换后的语素需共享“高位地形”语义场。
- 合法组合:高+顶→“高顶”(山顶的高处)。
- 非法示例:高+沙→“高沙”(语义冲突,沙无高位特征)。
- 语境验证:通过预训练语言模型(如BERT)判断生成词是否合理。 (这一步是发挥)
- 输入:“这座高顶海拔超过5000米” → 置信度>90%。
- 输入:“高沙堆积在山上” → 置信度<30%,被过滤。
Step 4:新词生成与评估
生成结果:
- 已有近义词:高峰 → 高岭、高顶(词典已有词)。
- 未登录新词:高峰 → 高峦(新造词)。
评估方法:
- 人工评估(通过ChatGPT模拟):
- 提问:“‘高峦’是否是一个合理的汉语词?请用1-5分评分(5=完全合理)。”
- 回答:“4分。‘峦’指连绵的山峰,‘高峦’可表示高大的山峦,符合汉语构词逻辑。”
- 语料验证:
- 在BCC语料库中搜索“高峦”,若未出现则标记为新词。
- 检查社交媒体(如微博)中是否有用户自发使用类似表达。
完整流程图
输入“高峰”
→ 语素拆分:“高” + “峰”
→ 语义解析(定中结构,地形类名词)
→ MIFSSM模型查找近义语素{岭, 顶, 峦}
→ 组配规则过滤(定中结构 + 语义场匹配)
→ 生成结果:高岭(已有词)、高顶(已有词)、高峦(新词)
→ 评估:人工打分 + 语料验证