@胡益裕等:《结合全局对应矩阵和相对位置信息的古汉语实体关系联合抽取》
主要讲这个模型是咋训练的,讲得还挺详细的。应该是非常典型的算法类论文?结构清晰:数据集→模型架构→实验验证
摘要
目前,基于全局对应矩阵的联合抽取模型在英文领域和现代汉语领域的实体关系抽取任务上取得了SOTA (state-of-the-art) 结果,然而在古汉语实体关系抽取任务上表现相对较差。这首先由于当前的古汉语实体关系数据集具有数据规模小、数据标注稀疏的特点,模型无法从数据中学习到足量的信息;其次是因为该模型训练时缺少实体的跨度信息,使得模型容易生成长度异常的实体。针对上述问题,该文在研究了开源的《资治通鉴》语料后,人工构建了一个古汉语实体关系数据集,并设计了一种结合全局对应矩阵和相对位置信息的实体关系联合抽取方法。该方法在古汉语实体关系数据集上的精确率和F1值分别达到了81.0%和67.0%, 相较于基线模型提升了6.8%和1.4%。同时,该文通过实验验证了上述融合相对位置信息的方法对于解决“容易生成长度异常实体”问题的有效性。
SOTA(State-of-the-Art)性能指的是在特定任务或领域中,当前表现最优的模型或算法所达到的最高水平。这一术语常见于机器学习领域,表示某个模型在特定数据集(如ImageNet)或任务(如图像分类、自然语言处理)的关键评估指标(如准确率)上超越了现有所有方法,成为技术前沿的标杆。
SOTA的实现不仅意味着性能优越,还可能涉及技术创新(如采用新算法或架构),并需通过严格验证(如基准测试和学术评审)。例如,AlphaFold因解决蛋白质结构预测难题而被视为SOTA模型,其突破性方法革新了行业标准。此外,SOTA状态是动态的,随着技术进步不断被刷新,研究者需持续迭代以保持领先。
1 引言
- 困难
- ①目前古汉语实体关系标注数据集较少;
- ②相较于现代汉语实体关系标注工作而言,古汉语实体关系标注工作在标注原则设定、标注类型选定等方面难度更大,要求标注人员具有扎实的古汉语专业知识。
- 现有二十四史语料数据的问题
- ①标注规模较小;
- ②在数据标注上存在标注稀疏问题,每条标注文本仅标注了少量的实体和关系。
- 本文贡献
- 本文继续构建了一个实体关系数更加丰富的《资治通鉴》数据集。
- 设计了一种结合全局对应矩阵和字与字之间相对位置信息的联合抽取方法。
1 相关研究
- 实体关系数据集构建
- WebNLG、NYT、SemEval、Chinese Literature Text、DuIE 2.0。
- “二十四史”实体关系数据集
- 王一钒等人提出了一套由“关系配价标注”“命名逻辑标注”以及“单一关系存在”原则构成的数据标注原则
- 实体抽取的办法
- 基于特征的方法
- 利用设置的特征函数获得数据特征信息,然后通过该特征信息联合识别实体和关系。
- 然而由于该方法在建立特征工程上严重依赖NLP工具和大量人工操作使得其难以处理数据规模较大的情况。
- 基于深度学习的方法
- 基于特殊标签识别的方法
- 基于序列生成的方法
- Sun等人→单标签任务
- Zeng 等人→LSTM 解决了三元组重叠问题
- Bert 类
- 一种“通过主体和关系识别客体”的实体关系联合抽取方法→由于该模型在实体头尾词匹配时采用“邻近匹配”原则,导致其无法处理嵌套实体问题。同时还因为该方法采用“先识别主体,后识别客体”的多阶段方式,使得模型存在错误传播问题。
- 嵌套实体解决方法(但是不同模块间缺乏信息的交互,从而使得实体和关系之间的相互约束不足,最终导致实体和关系在匹配时出现信息冗余问题)
- 一种利用大小为n×n(n为输入文本长度)的矩阵提取关系三元组的实体关系联合抽取方法。
- 将实体关系识别任务重新考虑为三元组序列生成任务,通过非自回归的解码方式生成三元组序列
- 基于全局对应矩阵的方法 :使用矩阵建模主客体之间、主客体和关系之间的关联信息,最终通过该关联信息完成对实体、关系的抽取
- 主要方法:
- Zheng等人和Shang等人:将实体关系任务划分为实体提取、主客体对齐和关系判断三个子任务,采用“先进行潜在关系预测,后完成主客体识别”的方式完成实体关系联合抽取。
- 在主客体对齐任务上,该方法主要利用一个全局对应矩阵学习主体和客体的关联性。虽然该方法提升了模型解决三元组重叠和嵌套实体问题的能力,然而由于该方法采用先预测潜在关系,后通过潜在关系完成主客体对齐任务的方式,使得潜在关系预测阶段出现的错误会传递到主、客体对齐任务上,即模型存在错误传播问题。
- Shang等设计了一种结合特殊标签和全局对应矩阵联合建模实体和关系的方法,该方法解决了上述的错误传播问题和信息冗余问题
- 在古汉语中容易生成长度较长的异常实体
- 其主要原因是:全局对应矩阵是通过实体头尾词来表示完整实体的,模型在学习实体信息时主要关注实体的头尾信息,较少关注实体的跨度信息,从而使得模型更难以精确地识别实体的边界
- 本文在全局对应矩阵上引入字与字之间相对位置信息的方法,最终通过大量实验证明了该方法的有效性。
- 主要方法:
- 基于特征的方法
2 数据集构建
| 特征类型 | 特征数量(个) | 平均准确率 |
| -------- | ------- | ------ |
| 词汇 | 25 | 62.92% |
| 句子 | 6 | 54.05% |
| 篇章[[ | 44 | 65.21% |
| 词汇+句子 | 31 | 63.23% |
| 词汇+篇章 | 69 | 67.74% |
| 句子+篇章 | 50 | 65.88% |
| 词汇+句子+篇章 | 75 | 67.85% |_type(主体类型)、object(客体)、object_type(客体类型)、relation(关系)等字段。
3 模型方法
3.1 模型概述
- 输入:句子
,其中 表示第 个字。 - 目标:识别序列S中所有的主体、客体和主客体的语义关系,并输出(主体,关系,客体)形式的三元组。
- 模型基于 Zheng 等人的 GCRP (Global Correspondence matrix and Relative Position based joint relational triple extraction) 模型,并使用 BERT 作为编码器。
- 三个子任务:主体和客体对齐、实体和关系对齐、实体抽取三个子任务
- 解码层架构:融合相对位置信息模块、主客体全局对应模块、实体关系全局对应模块、实体头尾全局对应模块
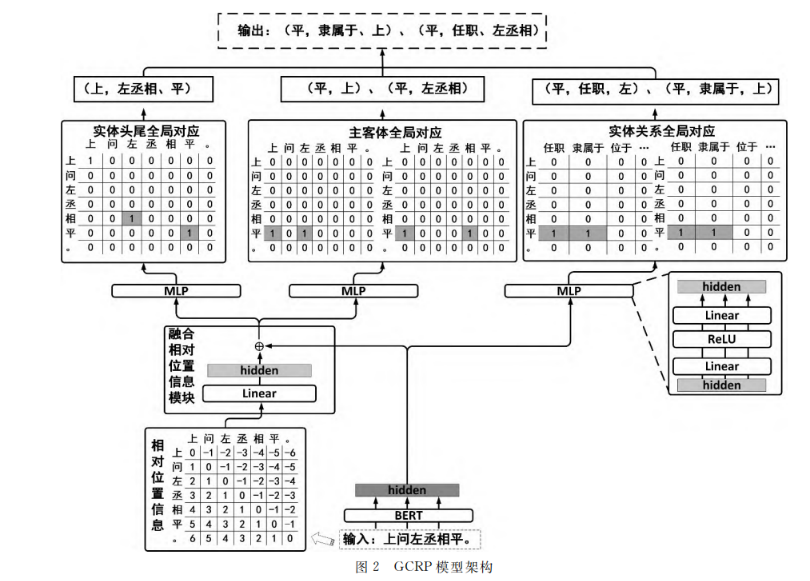
3.2 编码层
- 使用BERT将句子
编码为隐藏向量序列 :表示BERT最后一层输出的隐藏层状态,n为输入文本的长度。
3.3 解码层
3.3.1 位置编码
- 对于句子中的任意两个token
和 ,计算它们的相对位置编码: 是相对位置信息矩阵。 表示token 和 token 之间的距离。 和 是可学习的参数。 表示级联操作。
符号⊕ 通常表示向量或张量的级联操作(Concatenation),即沿着特定维度将两个或多个向量拼接成一个更高维度的向量。
3.3.2 主客体全局对应模块
- 本文选择将主体和客体的全局对应任务细分为主客体开始词对应和主客体结尾词对应两个子任务,并为每个子任务设计了对应的主客体开始词全局对应矩阵。
- 使用多层感知机(MLP)和Sigmoid函数预测token
和 token 分别作为关系头实体和客体的概率: 、 、 、 是可学习的参数。
3.3.3 实体关系全局对应模块
本文选择将其细化为主体开始词和关系的全局对应,以及客体开始词和关系的全局对应两个子任务,并设置了主体开始词和关系的全局对应矩阵(图4左半部分)和客体开始词和关系的全局对应矩阵(图4右半部分)。
、 、 、 是可学习的参数。
3.3.4 实体头尾全局对应模块
模型为矩阵中每个位置分配一个关联分数,该分数表示了该位置对应的(列元素,行元素)为(实体开始词,实体头尾词)的概率分数。当该分数大于设置的阈值时,为该位置分配标签“1”,否则分配标签“0”。其中,标签为“1”的(列元素,行元素)组合即为模型预测的(实体开始词,实体头尾词)
、 是可学习的参数。
3.4 损失函数
-
总损失函数
由三部分组成:对应矩阵损失 、实体识别损失 和 Head/Tail判断损失 : 。
-
对应矩阵损失
由头实体损失 和客体损失 组成: 。
-
实体识别损失
由头实体损失 和尾实体损失 组成: 。
-
Head/Tail判断损失
:
4 实验
4.1 实验设置
- 优化器:Adam
- 学习率:5e-5
- 最大序列长度:100
- Dropout:0.1
- Batch Size:8
- Epoch:100
- 权重:0.5
- MLP激活函数:ReLU
- 评估指标:Precision(精确率)、Recall(召回率)、F1-Score(F1值)
4.2 数据集划分
- 训练集、验证集、测试集比例为7:2:1。
| 实体类型 | 训练集 | 验证集 | 测试集 |
|---|---|---|---|
| PER | 8446 | 3167 | 1634 |
| JOB | 3828 | 1535 | 740 |
| LOC | 1752 | 664 | 346 |
| ORG | 474 | 142 | 104 |
| 总计 | 14500 | 5408 | 2824 |
| 关系类型 | 57 | 242 | 754 |
4.3 实验结果
4.3.1 不同BERT模型的影响
- 对比了Guwen-BERT、RoBERTa-classical-Chinese、SiKuBERT、SiKuRoBERTa以及BERT-ancient-Chinese-base-upos。
| 模型 | F1值(%) |
|---|---|
| Guwen-BERT | 65.0 |
| RoBERTa-classical-Chinese | 65.5 |
| SiKuBERT | 64.9 |
| SiKuRoBERTa | 65.7 |
| BERT-ancient-Chinese-base-upos | 67.0 |
- 结果表明,BERT-ancient-Chinese-base-upos表现最好。
4.3.2 不同方法在古汉语实体关系数据集上的性能对比
- 对比了CasRel、SPN4RE、OneRel、PRGC、TPLinker等模型。
| 模型 | Precision(%) | Recall(%) | F1值(%) |
|---|---|---|---|
| CasRel | 48.0 | 33.0 | 39.1 |
| SPN4RE | 51.1 | 40.6 | 45.2 |
| OneRel | 62.4 | 47.3 | 53.8 |
| PRGC | 69.0 | 52.1 | 59.4 |
| TPLinker | 74.8 | 58.4 | 65.6 |
| GCRP | 81.6 | 56.8 | 67.0 |
- 分析了关系分类(r)和实体识别(s, o)的F1值。
| 模型 | Precision(%) | Recall(%) | F1值(%) |
|---|---|---|---|
| TPLinker (r) | 88.1 | 63.5 | 73.8 |
| GCRP (r) | 91.9 | 59.9 | 72.5 |
| TPLinker (s, o) | 77.8 | 60.6 | 68.1 |
| GCRP (s, o) | 85.1 | 59.0 | 69.7 |
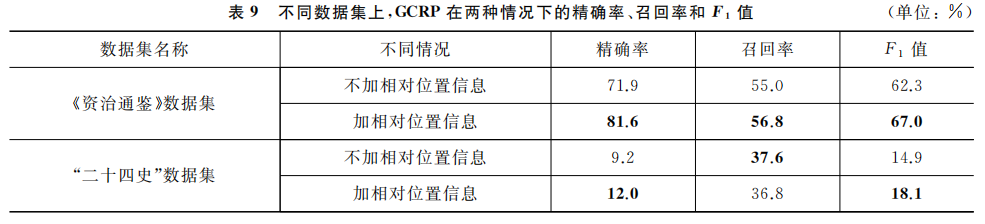
4.3.3 消融研究
消融研究是一种通过逐步移除模型中的特定组件,评估这些组件对整体性能影响的实验方法。其核心目的是验证模型中每个模块(如网络层、特征、损失函数等)的必要性和有效性。
- 类比理解:假设一辆汽车由发动机、轮胎、方向盘组成,消融研究类似于逐个移除这些部件,观察汽车是否还能行驶或性能如何变化。
5 结论
- 本文提出了一种结合全局对应矩阵和相对位置信息的古汉语实体关系联合抽取方法。
- 实验结果表明,该方法在古汉语数据集上取得了较好的效果。