@跨现代和历史文化中人类关系的概念结构The conceptual structure of human relationships across modern and historical cultures
现代和历史文化中人类关系的概念结构
基本信息
摘要
A defining characteristic of social complexity in Homo sapiens is the diversity of our relationships. We build connections of various types in our families, workplaces, neighbourhoods and online communities. How do we make sense of such complex systems of human relationships? The basic organization of relationships has long been studied in the social sciences, but no consensus has been reached. Here, by using online surveys, laboratory cognitive tasks and natural language processing in diverse modern cultures across the world (n = 20,427) and ancient cultures spanning 3,000 years of history, we examined universality and cultural variability in the ways that people conceptualize relationships. We discovered a universal representational space for relationship concepts, comprising five principal dimensions (formality, activeness, valence, exchange and equality) and three core categories (hostile, public and private relationships). Our work reveals the fundamental cognitive constructs and cultural principles of human relationship knowledge and advances our understanding of human sociality.
本研究通过在线调查、实验室认知任务和自然语言处理(NLP)技术,探索了人类关系的概念结构在现代和历史文化中的普遍性与文化变异。研究提出了一个通用的五维模型——FAVEE(形式性、活跃性、情感价值、交换、平等),以及三个核心关系类别——敌对、公共、私人(统称为FAVEE-HPP)。研究数据来自全球现代文化的20,427 名参与者,并分析了跨越3,000 年的历史文化文本。
- 核心结论: FAVEE-HPP 框架为人类关系提供了一个跨时间、跨社会的统一表征。
引言
核心问题
- 人类生活离不开关系的建立、维持与调整,关系的质量和数量对生存和幸福至关重要。
- 社会隔离和不良关系会影响个体的认知、行为、发展和幸福感。
研究挑战
- 关系的多样性与复杂性:
- 相比非人类灵长类的等级和亲密关系,人类关系更加多样(如“亦敌亦友”、“教父母”、“网友”),且依赖上下文,涉及时间、空间、情感和文化规范等因素。
- 主观性:
- 关系是个体信念、经验和实践的产物,受个人视角和动态规则影响,难以建立客观统一的衡量标准。
- 跨学科差异:
- 社会学、人类学、认知心理学和传播学从不同视角研究关系,提出了各自的理论(如社会学的“三因素模型”、人类学的“四种社会联结形式”),但缺乏统一框架。
研究目标
- 聚焦普通人对关系的“常识”理解,构建跨学科统一框架,揭示关系概念的基本元素和组织结构,探索其跨文化和跨历史的普遍性与变异性。
结果
研究 1:跨学科的统一表征空间
方法
- 特征选择:
- 通过文献综述(见扩展数据图 1),从 15 个重要理论中提取 30 个关系概念特征(如活跃性、共性、平等性等,详见补充表 1)。
- 关系生成:
- 使用自然语言处理(NLP)模型生成 159 种典型关系,包括常见(如“兄弟姐妹”)和不常见(如“主仆”)关系(详见补充表 2)。
- 在线调查:
- 招募 1,065 名美国本土英语使用者,通过 MTurk 完成在线调查,评分 159 种关系在 30 个特征上的表现。
- 主成分分析(PCA):
- 将高维特征集降维为五个正交潜在因子。
- 认知任务:
- 60 名美国参与者在实验室完成维度调查、多重排列任务和自由分类任务,考察关系的分类表征。
- 多排列任务:参与者通过在 2D 计算机屏幕上排列 159 种关系来判断它们之间的相似性,使得任何两种关系之间的距离反映了它们的概念差异
- 自由分类任务中,参与者将同一组关系分类到他们选择的标签类别中。
- 60 名美国参与者在实验室完成维度调查、多重排列任务和自由分类任务,考察关系的分类表征。
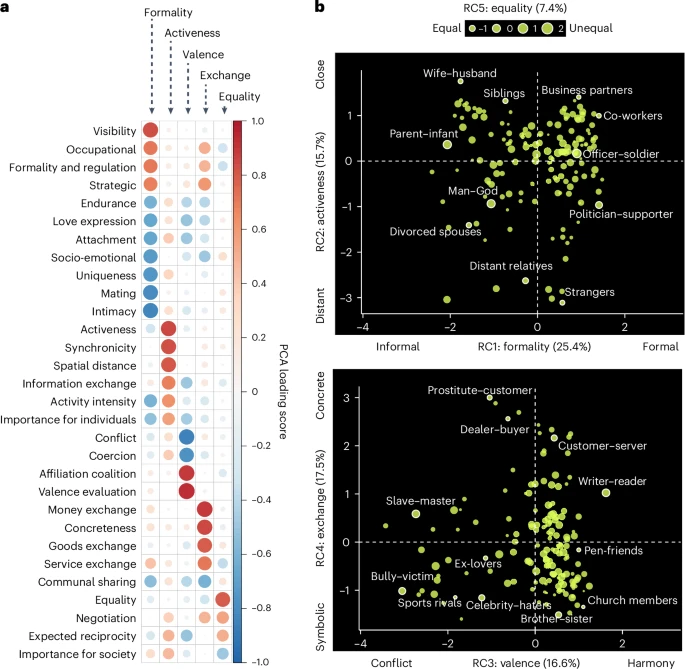
结果
- 五维模型(FAVEE):
- 正式性(Formality): 区分正式、职业性关系(如同事)与非正式、社会情感关系(如父母-婴儿)。
- 活跃性(Activeness): 区分亲密关系(如夫妻)与疏远关系(如陌生人)。
- 效价(Valence): 区分友好和谐(如教会成员)与冲突敌对(如奴隶-主人)关系。
- 交换(Exchange): 区分具体资源交换(如买卖双方)与象征资源交换(如名人-黑粉)关系。
- 平等(Equality): 区分权力平等(如体育对手)与不平等(如人-神)关系。
- 其他降维方法(如独立成分分析、探索性因子分析)验证了五维结构的稳健性(见补充图 3)。
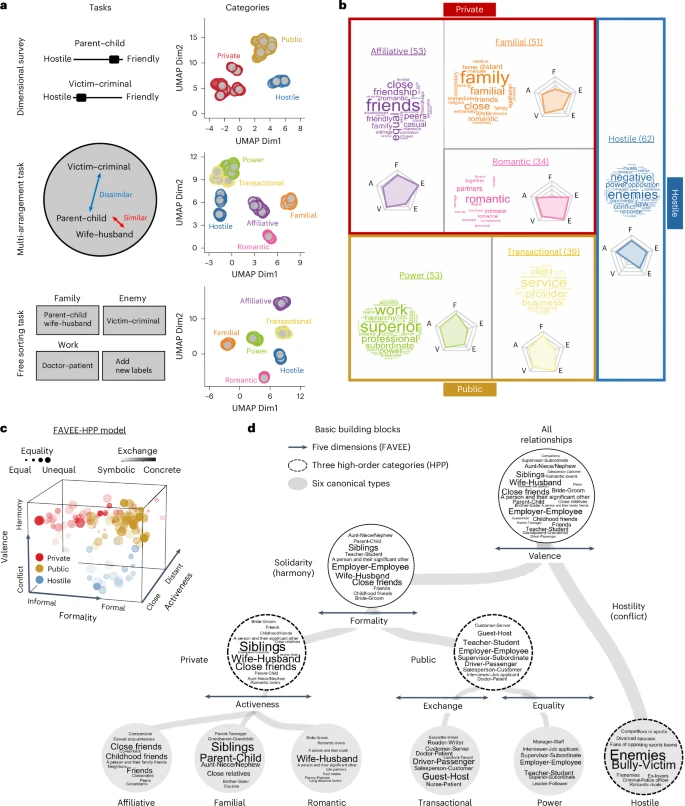
- 分类表征(HPP):
- 聚类分析识别出三个高级类别:
- 敌对(Hostile): 如离婚配偶、商业对手。
- 私人(Private): 如兄弟姐妹、密友。
- 公共(Public): 如司机-乘客、雇主-雇员。
- 认知任务进一步揭示六个典型关系类型(敌对、家庭、浪漫、亲和、交易、权力),源于 HPP 类别(见图 2)。
- 聚类分析识别出三个高级类别:
- 维度-类别混合模型:
- HPP 类别嵌入 FAVEE 五维空间,表明类别可能源自维度分布(见图 2 c, d)。
研究 2:现代文化中的普遍性与变异性
所有人类文化都有丰富的词汇用于描述人际关系。例如,翻译词典表明,英语单词“neighbours”可以等同于中文单词“邻居”和希伯来语单词“שכנים”。然而,这是否意味着“邻居”的概念在美国、中国和以色列是相同的?在研究 2 中,我们通过考察 19 个全球地区和 10 种语言中关系概念的表示来探讨这个问题。我们的目标是揭示跨文化的相似性和差异及其潜在的文化机制。
方法
- 参与者:
- 招募 17,686 名来自 19 个全球地区的在线参与者,覆盖 10 种语言(见补充图 13)。
- 调查:
- 参与者对关系在 33 个特征上评分(新增道德、信任、代沟特征)。
- 分析:
- 对于每个地区,基于表征差异矩阵(RDMs)生成了三种类型的表征几何结构:全特征模型(即基于所有评估特征原始数据的 RDMs,不应用任何降维或聚类技术)、维度模型(即基于 FAVEE 的 RDMs)和分类模型(即基于 HPP 的 RDMs)。 基于这些特定区域的表征几何模型,评估了关系概念在跨文化中的一致性程度。
- 使用表征相似性分析(RSA)考察关系的表征几何一致性和变异性
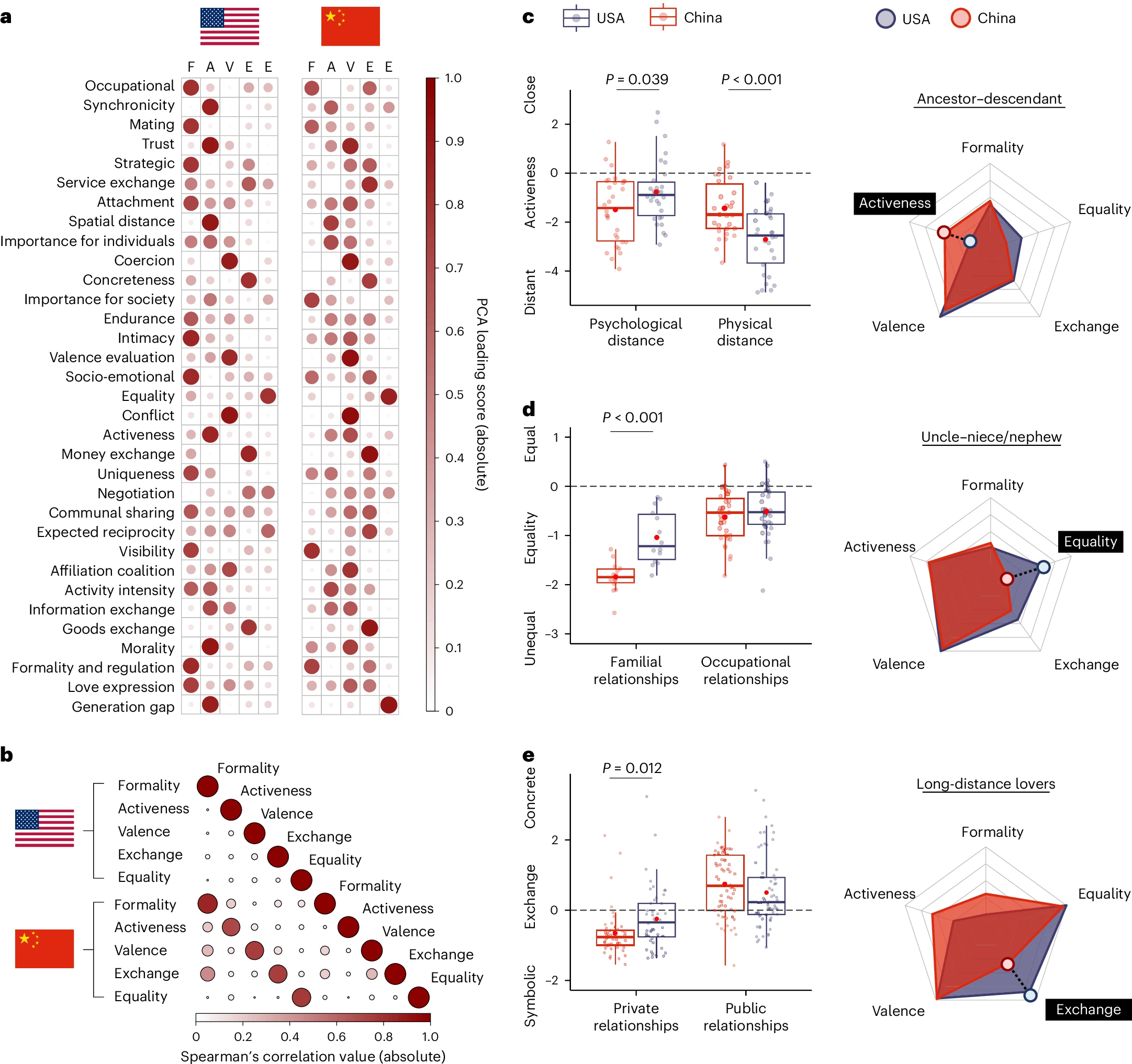
- 中美两国在人际关系理解上的文化差异
- 在中国额外收集了6,128份数据(见补充图8),并将其与美国的数据进行了直接对比(见图4)。
- 为了排除语言和翻译可能带来的影响,研究者进行了两轮数据收集:
- 第一轮:使用了从美国关系列表直接翻译而来的159种关系。
- 第二轮:通过中文自然语言处理(NLP)算法生成了258种关系,其中包括许多中国特有的关系类型,有些无法直接翻译,有些则是中国文化独有的(具体列表见补充表4)。
- 研究发现,直接翻译的关系数据集与中文NLP生成的关系数据集之间没有显著差异(所有相关系数 r > 0.622,P < 0.001;见补充图8)。这表明研究结果不受语言或翻译的影响,增强了结论的可靠性。
- 对于每个地区,基于表征差异矩阵(RDMs)生成了三种类型的表征几何结构:全特征模型(即基于所有评估特征原始数据的 RDMs,不应用任何降维或聚类技术)、维度模型(即基于 FAVEE 的 RDMs)和分类模型(即基于 HPP 的 RDMs)。 基于这些特定区域的表征几何模型,评估了关系概念在跨文化中的一致性程度。
结果
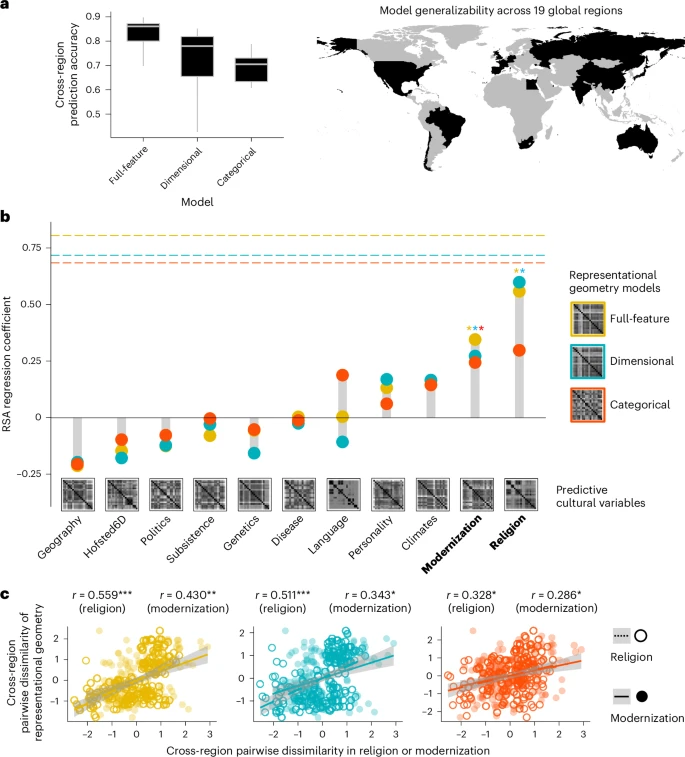
- 普遍性:
- FAVEE 和 HPP 模型在全球范围内共享,通过留一法交叉验证确认(见图 3 a)。
- FAVEE 模型优于 15 个现有理论,解释了更多跨文化方差(见扩展数据图 3)。
- 文化变异:
- 影响因素: 宗教和现代化水平显著预测表征几何的跨区域变异(见图 3 b, c)。
- 具体差异:
- 公共关系的理解因文化而异,但家庭和浪漫关系的概念较为一致(见扩展数据图 4)。
- 中美对比(见图 4):
- 亲密性: 美国人更关注物理距离(如祖先-后代被视为疏远),中国人强调心理距离(因儒家祖先崇拜视为较亲密)。
- 权力: 中国人对家庭关系(如叔侄)的不平等刻板印象更强。
- 交换: 美国人在私人关系中更多具体资源交换(如远距离恋人互赠礼物),中国人偏向象征性交换(如长电话)。
- 非工业社会验证:
- 在中国摩梭族(229 名参与者)中,FAVEE-HPP 结构依然适用(见扩展数据图 5)。
研究 3:古代文化中的关系表征
方法
- NLP 技术:
- 使用预训练语言模型(PLM)和大型语言模型(LLM,如 GPT-4)分析现代和古代中文文本。
- 查询格式:"[DESC] 关系 [TERM] 的最显著特征是 [MASK]",提取[MASK]的上下文嵌入。
- 古代数据:
- 分析从周朝(公元前 1046 年)至清朝(1912 年)的历史中文语料库。
- 专家校正描述,确保符合古代语境(见补充方法 2)。
- 验证:
- 44 名古代文化专家评分 120 种古代关系,验证 PLM 结果。
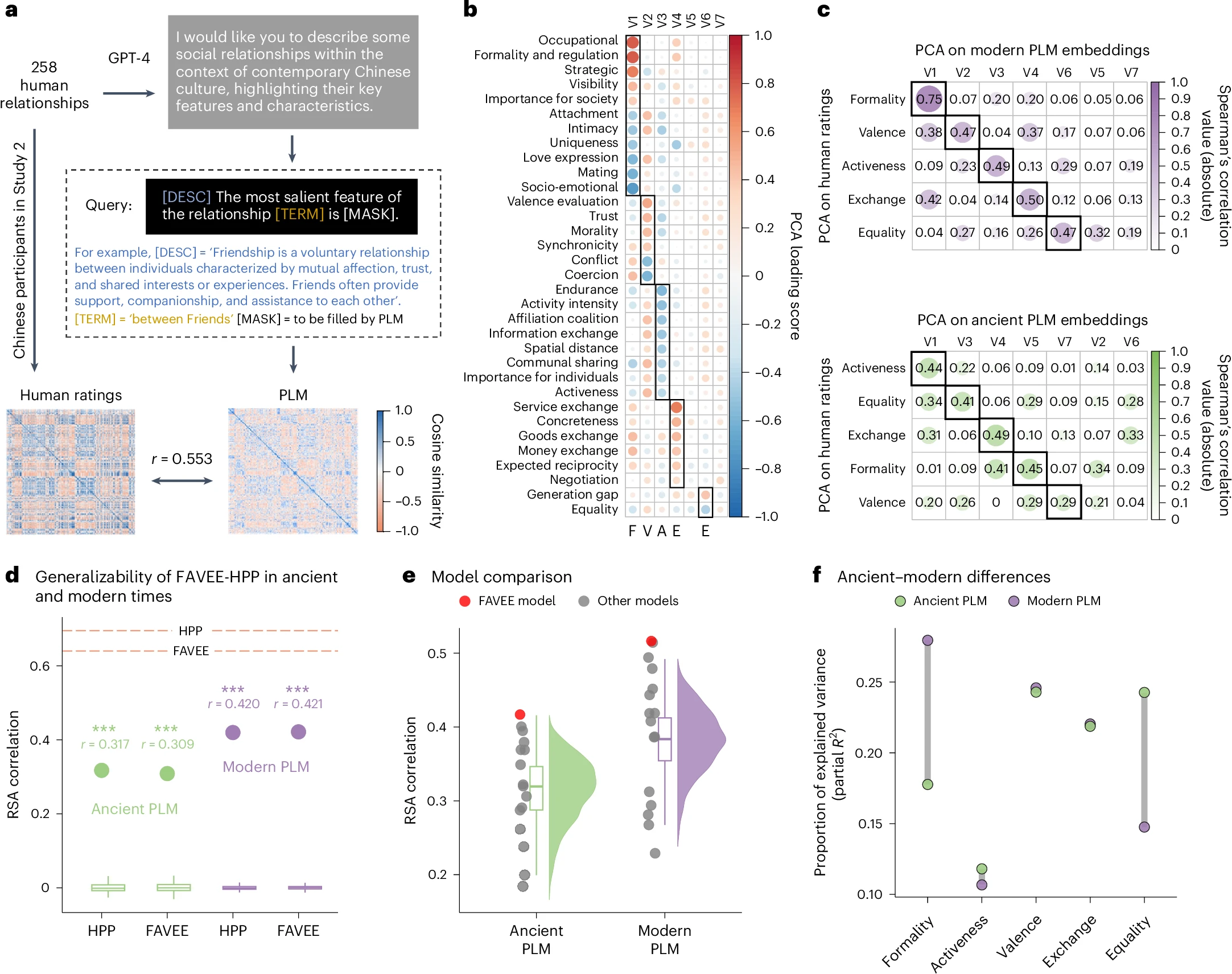
结果
- PLM 有效性:
- 现代 PLM 嵌入与人类评分高度相关(r = 0.553, P < 0.001),PCA 提取的成分对应 FAVEE 结构(见图 5 a-c)。
- 古代适用性:
- FAVEE-HPP 模型适用于古代中国关系表征,RSA 确认其预测能力(见图 5 d)。
- FAVEE 优于其他理论(见图 5 e)。
- 古今差异:
- 正式性: 现代更强调(如职业关系)。
- 平等性: 古代更关注(如社会等级)。
- 古代 PLM 与专家评分一致,反映专业知识(见补充图 10)。
讨论
主要发现
- 统一框架: FAVEE-HPP 整合多学科理论,揭示关系概念的五维空间和三类结构。
- 普遍性: 该框架在现代和历史文化中一致,优于现有模型。
- 汇聚的证据表明,FAVEE-HPP 框架在现代社会(研究 2)和历史文化(研究 3)中普遍共享,并且在模型性能(补充图 6)、全球区域一致性(扩展数据图 3)和时间持久性(图 5e)方面超越了现有理论。我们还将 FAVEE 框架扩展到非二元关系(扩展数据图 7),并确认了其对三元关系(例如,三角恋)和群体关系(例如,贫富、民主党-共和党)的普遍适用性。
- 变异性: 宗教和现代化影响现代变异,正式性和平等随时间变化。
理论与实践意义
- 社会性与认知: FAVEE-HPP 可用于研究社会性如何驱动认知进化。
- 应用: 提供量化框架,类似“大五”人格模型,适用于关系科学研究。
未来方向
- 未来的研究可以探讨人类发展过程中关系表征是如何构建的,以及我们如何形成对关系的独特印象。
- 局限性:
- 当前聚焦“常识”而非实际关系组织。
- 数据依赖在线人群,需更多验证。
- 古代研究限于中国,需扩展至其他文化。
方法
参与者
- 研究 1: 1,065 名在线美国参与者(MTurk),60 名线下参与者。
- 研究 2: 17,686 名全球 19 区参与者,229 名摩梭族成员。
- 研究 3: 44 名古代中国文化专家。
数据收集
- 关系采样: Sampling of human relationships
- 采用基于自然语言处理(NLP)的数据驱动方法生成了全面的人际关系列表(详见补充方法 1)。通过头脑风暴和社交媒体搜索,一组参与者(美国 n=15,中国 n=27)创建了种子词。
- 利用文本嵌入技术,通过计算词向量间的余弦距离,找出与种子词高度共现的词汇。筛选后仅保留名词,进一步根据频率过滤并人工核查,确保仅保留与人际关系相关的词汇。
- 随后,基于关系含义配对词汇,并补充从文献中提取的关系,最终形成了人际关系词汇表(美国 159 个,中国 258 个)。
- Evaluative features 评价特征
- 进行了全面的文献检索,以找到所有探索人类关系基本形式的相关理论和模型。在研究 1 中,从 15 个重要理论中总结并提取了 30 个概念特征。跨理论合并了冗余特征(详见扩展数据图 1 和补充表 1)。需要注意的是,这些理论特征中的许多最初是通过降维或聚类技术得出的,但在这里它们被准备进一步简化为更高阶的组成部分。
- 研究 2 从跨文化文献中增加了三个额外的理论特征(道德、信任和代沟),因此总共评估了 33 个特征。
- 维度调查:Dimensional survey
- 参与者用双极 Likert 量表评分关系特征。
- 认知任务: Cognitive tasks
- 多排列任务是一种行为范式,用于收集对语义概念的直观相似性判断。参与者被要求在计算机屏幕上的二维圆中通过鼠标拖放“根据相似性排列 159 种关系”,以便将相似的关系放在一起,不相似的关系则分开放置。
- 自由分类任务要求参与者有意识地将159种关系分类到标记的类别中。他们可以根据自己的喜好进行任意数量的分组(最多八个)。
- 对自由分类任务中参与者分配的类别标签进行了文本分析。最初获得了 444 个标签,并通过分配 159 种关系(444×159 矩阵)进行编码。例如,“家庭”标签被分配给“妻子-丈夫”而不是“医生-患者”,因此前者编码为 1,后者编码为 0。对标签×关系矩阵进行了层次聚类(Ward 方法)。在排除包含杂项标签的噪声聚类后,在剩余的 292 个标签上观察到了三个和六个聚类。
分析方法
- 降维: PCA 提取五维 FAVEE 模型。
- 由于 PCA 不提供组件的标签,我们通过考虑前五个最高加载(绝对值)和关系评分的分布来命名这些组件。为了确定最佳的 PCA 组件数量,我们检查了四个数据驱动的指标(即平行分析、Kaiser-Guttman 规则、Cattell 的碎石检验和最优坐标),并检查了每个组件的可解释性(扩展数据图 2a)。选择了具有跨指标一致性和高可解释性的解决方案。
- 我们还实施了其他降维技术以验证 PCA 结果(详见补充图 3),并使用独立成分分析、探索性因子分析、多维尺度和网络分析观察到了五个相同的组件。
- 聚类: k-means
- 语言模型: 现代:中文RoBERTa-Base,古代:BERT-ancient-Chinese
- RSA: 评估跨文化变异和模型预测能力。
表征相似性分析 RSA(Representational Similarity Analysis, RSA)
研究目标
研究者希望了解哪些文化因素(如语言、人格、社会生态、现代化等)影响了不同地区人们对关系的表征差异。
方法步骤
- 数据收集:
- 从多个开放数据库(如世界价值观调查、世界银行等)收集了全球各区域的文化变量数据。
- 这些变量包括语言、人格、社会生态(生存方式、历史疾病流行率、气候)、现代化、遗传、宗教、政治以及霍夫斯泰德6D文化模型。
- 文化变量RDM的构建:
- 对于每个文化变量(例如现代化),构建一个RDM(表征不相似性矩阵)。
- RDM中的每个单元格表示两个区域在该变量上的差异,例如中国和葡萄牙在现代化水平上的不相似性。
- 关系表征RDM的构建:
- 对于关系表征的几何形式(全特征、维度或类别),也构建一个RDM,表示不同区域之间关系表征的不相似性。
- 多元回归分析:
- 使用线性回归模型,将文化变量RDM作为预测变量,关系表征RDM作为结果变量。
- 通过回归分析,探究哪些文化变量对关系表征的跨文化差异有显著贡献。
- 噪声上限估计:
- 用n-1个区域的平均关系RDM预测剩余一个区域的关系RDM,估计噪声上限。
- 这反映了关系表征RDM固有的异质性,即数据中不可避免的随机噪声水平。
- 统计显著性检验:
- 使用Mantel检验评估RSA结果的显著性。
- 方法是:在保持关系表征RDM不变的情况下,随机排列文化变量RDM的顺序,重新计算回归,重复10,000次。
- 根据多元回归的F统计量计算P值,采用单侧检验(因为只关注正相关性,负值无意义)。
结论

本研究通过跨学科、跨文化和跨历史的方法,揭示了人类关系概念的普遍结构(FAVEE-HPP)和文化变异性,为理解人类社会性提供了新视角和工具。