@陈欣等:《基于大语言模型的试题自动生成路径研究》
对比一下 @来雨轩等:《基于大语言模型与检索增强的学科试题生成方法》
摘要
为提高大模型自动生成试题的质量,本研究构建一种基于大语言模型的试题自动生成路径,并对其进行验证研究。首先是基于检索增强进行知识集成,其次是将课程知识以知识点的形式融入提示模板,最后是结合提示工程的效用,使大模型在理解课程知识的基础上执行大量试题生成任务。验证结果发现,自动生成试题的合格率为86.47%,随机抽取试题组成的测验难度为0.67,试题接受度良好。
一、研究背景
1. 国际研究进展
- 传统AQG方法局限 基于模板/规则/统计的自动问题生成方法难以适应复杂任务
- LLM技术突破
- GPT系列实现端到端测验生成(Dijkstra, 2022) → 生成含高质量干扰项的多选题
- ChatGPT-3支持交互式命题与自动评分(Attali, 2022) → 专家评估通过率超80%
2. 大模型应用挑战
- 核心缺陷 ▶️ 黑盒模型可解释性缺失 ▶️ 知识更新延迟(无法获取最新数据) ▶️ 专业知识不足导致的"幻觉"现象
- 解决方案——检索增强生成(RAG)
- Meta AI首创参数+非参数混合模型(2020) → 知识密集型任务准确率提升23%
- LangChain框架实现知识点精准匹配(Li, 2023)
- 外部数据源扩展: ✔️ 学科知识图谱 ✔️ 教学场景数据 ✔️ 专家知识库
3. 提示工程突破
- 国际前沿方法
- 知识图谱子图提示
- 思维链(Chain-of-thought)
- 教师集体知识模板
二、方法框架(GQR路径)
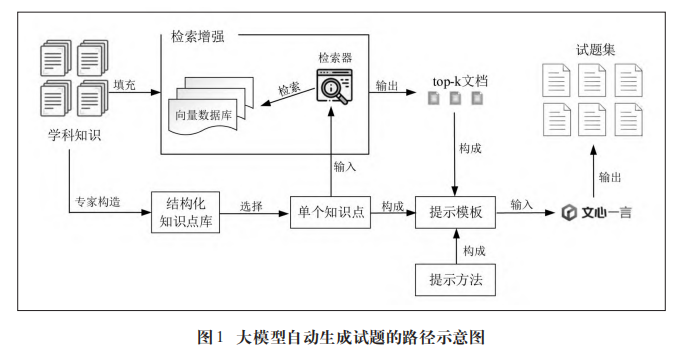
1. 知识增强
- 实现方式:
- 文心千帆平台知识库插件
- 向量数据库 通过调用API的方式使用文心Embedding_V1模型作为检索器
- 参数设置:
{"temperature":0.95, "top_p":0, "penalty_score":1}
2. 结构化知识点
首先,在专家和教师经验的指导下,将一门课中需要学生掌握的内容按知识点的形式进行组织,形成知识点条目的结构化数据。其次,通过调用大模型应用接口(application programming interface,API),既可以遍历(traversal)存储文件让知识点条目逐一自动填补进提示模板中,也可以在交互界面填入提示模板,指令大模型进行试题的批量化生成。
3. 提示模板设计
最终指令模板
你是一位教授[科目]这门课的老师,现在想要考查学生对所学的[top-k 文档在代码中的参数]中知识的掌握程度,根据该目的,你要执行下列任务:
1)分析关于[知识点]的内容;
2)编制一道[题型];
3)给出正确答案和解释。
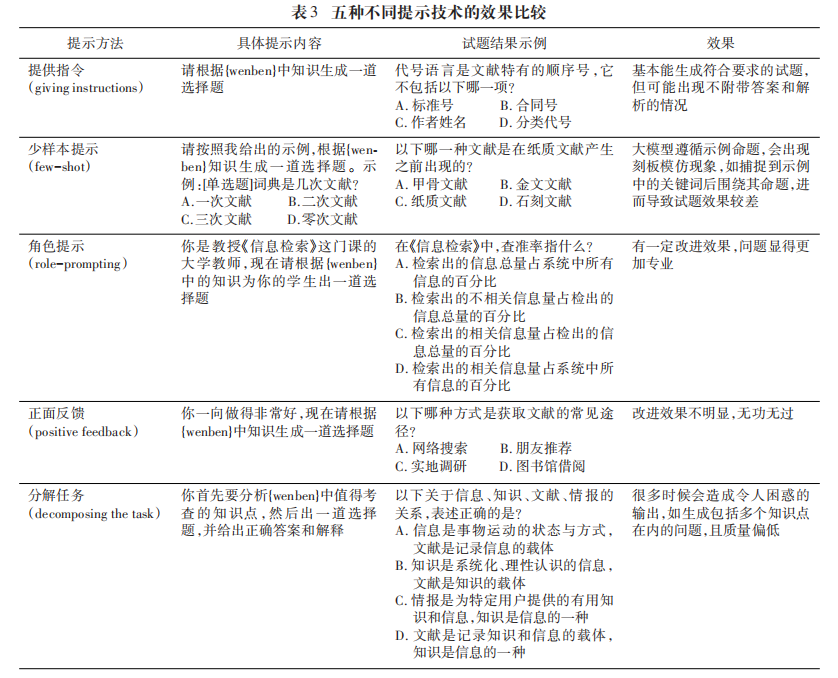
提示技术对比
三、验证研究
评估体系
-
五维合格标准:
- 准确性
- 模板黏性
- 完善性
- 试题质量
- 道德性
-
难度公式:
(X:平均分,W:总分)
实验结果
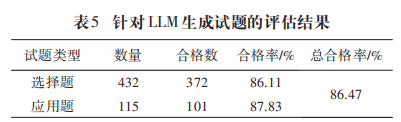
抽取10名上学期选修《信息检索》与《数据结构》课的全日制在读硕士生作为被试,并告知他们这是一次考查信息素养的测试,要求他们独立完成并尽可能准确作答。测验结束后进行难度值计算,结果P值为0.67
四、局限与展望
当前局限
- 单题难度控制机制缺失
- 复杂题型(五选项)生成 试题质量受损
- API 暂时无法给出有正确代码缩进的代码(Cm:: 疑惑,用 md 格式不行吗?平时也 api 写代码也写得好好的)
- API 在生成图画方面的能力还比较欠缺(Cm:: 疑惑,不能用 mermaid 画图吗?)
未来方向
- 领域专用模型微调
- 探索更多灵活的任务提示模板
- 多轮对话质量优化