@雷蕾等《AlphaReadabilityChinese:汉语文本可读性工具开发与应用》
摘要
【背景】文本可读性是文本的重要语言特征,已被广泛应用于多个学科的研究。现有可读性研究大多聚焦于英语文本可读性指标和工具的开发,而针对汉语的研究尚处于起步阶段。另外,相关研究多采用词汇和句法等表层特征,且主要聚焦国际中文教育教材和学习者文本。
【方法】本文旨在报告我们开发的汉语文本可读性工具AlphaReadabilityChinese。该工具包括词汇、句法、语义三个维度共九个语言指标,采用了更成熟、稳健的算法开发,是通用的汉语可读性指标和工具。
【实验】本文以金庸和古龙两位作家的作品为语料测试该工具的有效性。结果显示,两位作家的作品在可读性指标上具有较大差异,金庸作品文本的可读性显著弱于古龙作品。
【结果】测试结果同时表明,该工具所包含的可读性指标可以很好地区分两位作家的作品。论文最后分析了AlphaReadabilityChinese在数字人文、国际中文教育、新闻传播、信息科学、经济/金融等学科领域的应用前景。
1. 引言
1. 文本可读性的定义与重要性
- 文本可读性指文本的难易程度,是衡量文本语言特征的关键指标。
- 其重要性体现在多领域应用,如信息科学(Lei & Yan 2016)、新闻传播学(Graefe et al. 2018)、经济学/金融学(Aldoseri & Melegy 2023)等。
2. 早期经典指标
- 特征:早期指标基于简单语言特征,如句子长度、单词长度(字母或音节数)、难词(低频词)等。
- 代表性指标:
- Flesch Reading Ease(1948):使用句子总数、单词总数、音节总数计算,
公式为 206.835 - 1.015 × (单词总数/句子总数) - 84.6 × (音节总数/单词总数)。 - SMOG(1969):仅基于多音节单词数,公式为
3 + √多音节单词数。 - New Dale-Chall(1995):结合平均句长、单词总数、难词总数(四年级词表外单词),公式为
64 - 0.95 × (100 × 难词总数/单词总数) + 0.69 × 平均句长。
- Flesch Reading Ease(1948):使用句子总数、单词总数、音节总数计算,
- 特点:计算简单,应用广泛,但仅限于表层语言特征。
3. 经典指标的局限性
- 未考虑句法、语义、连贯性等深层特征,导致准确性受限。
- 促使学者开发更全面的指标和工具。
4. 现代研究的进展
- 英语研究:
- Crossley等(2019)综合形象性(imageability)、字符熵、词汇的具体性(concreteness)和语义独特性,提出新指标。
- Crossley等(2023)引入句嵌套和BERT模型,优化算法。
- 汉语研究:
- 早期基于字、词、句等表层特征,如Yang(1971)用39个特征构建公式,最终包括难词比、完整句子数、汉字平均笔画数。
- 近年纳入语法、篇章、语义特征:
- 朱君辉等(2022)提取572条语法特征,分级中文教材。
- 吴思远等(2020)用104项特征(汉字、词汇、句法、篇章)分析课本,所有语言特征指标中预测力最强的是汉字熟悉度、汉字多样性、词汇多样性、短语句法结构复杂度、词汇熟悉度等指标。
- 程勇等(2020)发现字频、词义丰富度、连词比例是关键。
5. 应用领域
- 语言教学:教材难度分级。
- 经济学/金融学:年报可读性反映信息披露质量,受数字化转型影响(王海芳等 2022)。
- 图书情报科学:学术论文可读性低引用率高,但社交媒体传播率低(刘宇等 2023;欧桂燕等 2023)。
- 数字人文:分析文学风格,如金庸、古龙小说对比(刘颖和肖天久 2014)。
6. 现有研究的局限性
- 英语主导:汉语研究起步晚。
- 维度单一:多基于表层特征,少见语义、篇章分析。
- 方法简单:依赖长度、频次计算,缺乏复杂算法。
- 适用性窄:主要服务国际中文教育,其他领域验证不足。
7. 本研究的贡献
- 开发工具AlphaReadabilityChinese(ARC):
- 包含词汇、句法、语义等多维度指标。
- 采用成熟算法,提升计算稳健性。
- 定位通用工具,适用多领域研究。
- 通过数字人文研究(如金庸、古龙小说分析)验证有效性。
2. 汉语文本可读性工具开发
-
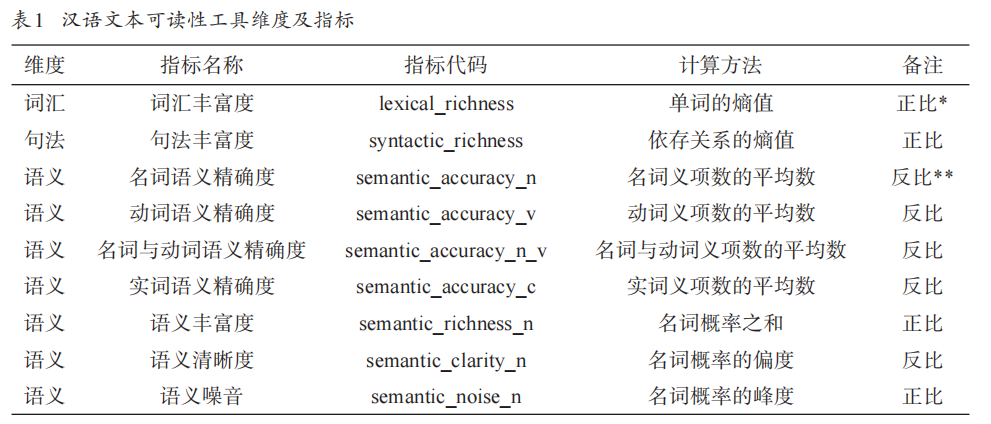
ARC包含三个维度九个指标,见表1:
注:
- 正比:指标值越大,文本难度越大,越难读。
- 反比:指标值越大,文本难度越小,越易读。
2.1 词汇丰富度
- 计算公式:
为表示第 i个单词在文本中出现的概率或相对频次, 为表示文本中所有独特单词的数量,熵值越大,词汇越丰富,文本越难读。 = 文本中所有单词的总数 / 第 i 个单词在文本中的出现次数
1 忽略分布均匀性
字符种类数(Unique Character Count)仅统计文本中不同字符的数量,但无法反映字符的实际分布模式。例如,若两个文本具有相同的字符种类数,但其中一个文本中某几个字符高度集中(如"的、了、是"占90%频次),另一个文本的字符分布均匀,两者的词汇丰富度显然不同。
2 对文本长度敏感
字符种类数易受文本长度影响。短文本的字符种类数可能远低于长文本,但这并不意味着其词汇丰富度更低。例如,一篇100字的短文可能使用50种字符,而一篇1000字的文章使用150种字符,但后者可能因高频重复某些词导致实际词汇变化较少。
熵值通过概率归一化(
2.2 句法丰富度
- 使用依存关系熵值计算,公式同上,熵值越大,句法越复杂,文本越难读。
2.3 语义精确度
- 计算实词(名词、动词等)义项数平均值:
为义项数, 为实词总数,义项数越多,语义越不精确,文本越易读。
2.4 语义丰富度
- 计算名词概率之和:
- 话题越丰富,文本越难读。
为名词在文本中出现的概率或相对频次, 为文本的名词总数。
2.5 语义清晰度
- 计算名词概率偏度:偏度测量的是数据观测分布与数据正态分布的偏离方向和程度。文本中话题分布概率越向右偏离正态分布,则其话题越集中,语义越清晰。
- 右偏分布(偏度为正):大多数名词的出现概率较低,少数名词的概率较高,意味着话题集中,语义清晰。
- 均匀分布(偏度接近零):名词的出现概率较为平均,话题分散,语义不够清晰。
$$
\text{SC} = \frac{1}{N} \sum_{i=1}^{n} \left[ \max(P) - P_i \right]
$$
- 计算文本中名词出现概率的偏度,也就是文本的语义清晰度。语义清晰度值越大,说明文本以名词为代表的话题越集中,其语义越清晰。
:第 个名词在文本中出现的概率或相对频次。 :文本的单词总数(包括所有词性,不仅仅是名词)。 :文本中名词的总数(不同名词的数量)。 :所有名词中出现概率最大的值。 - 这个公式通过测量每个名词的概率
与最大概率 的偏离程度,来反映名词概率分布的集中性。
2.6 语义噪音
-
峰度测量的是随机变量概率分布的陡峭程度以及概率分布的尾度(tailness)。
-
文本中话题分布概率的峰度越大,其尾度越厚,则话题分布越偏向于不重要的话题,文本的语义噪音越大。
- 峰度越大:话题分布的尾部越厚,意味着文本中存在较多低概率的话题(即不重要的话题),这些低概率话题构成了语义上的“噪音”,使文本的主题分散,语义噪音较大。
- 峰度越小:话题分布较为集中,尾部较薄,说明文本主要由高概率的话题(重要话题)主导,语义噪音较小,主题清晰。
-
计算名词概率峰度:
-
符号
- n:文本中不同名词的总数。
:第 个名词在文本中出现的概率或相对频次(例如,某名词出现次数除以所有名词的总出现次数)。 :所有名词出现概率的平均值,即 。
-
公式解释
- 分子
:这是四阶中心矩,计算每个名词概率与平均概率偏差的四次方之和。四次方放大了极端值(即非常高或非常低的概率)的贡献。 - 分母
:这是方差的平方(二阶中心矩的平方),衡量概率分布的离散程度。
- 分子
-
整体公式:峰度是四阶中心矩与方差平方的比值,再乘以名词总数
。 -
技术实现:
- 分词和依存句法分析:哈尔滨工业大学LTP。
- 义项数计算:清华大学OpenHowNet。
3. 验证汉语文本可读性工具:文学作品研究案例
3.1 研究目的、数据与方法
- 目的:比较金庸和古龙小说可读性差异,验证ARC效度。
- 数据:金庸6部小说(《射雕英雄传》等),古龙6部小说(《大旗英雄传》等)。
- 问题
- (1) 金庸和古龙小说作品在可读性特征上是否存在差异?
- (2) 可读性指标是否可以区分金庸和古龙小说作品?
- 方法:
- 使用ARC计算九个指标。
- T检验比较差异→是否存在显著差异
- 层次聚类(Ward方法)。
- 先对ARC所包含的九个可读性指标值做归一化处理,
- 并基于归一化后的可读性指标值来计算文本的欧几里得距离。
- 然后,计算聚类系数(agglomerative coefficient),以确定聚类连结方法(clusteringlink agemethod)。
- 由于Ward方法的聚类连结系数最大,我们确定以Ward方法连结聚类。
3.2 研究结果与讨论
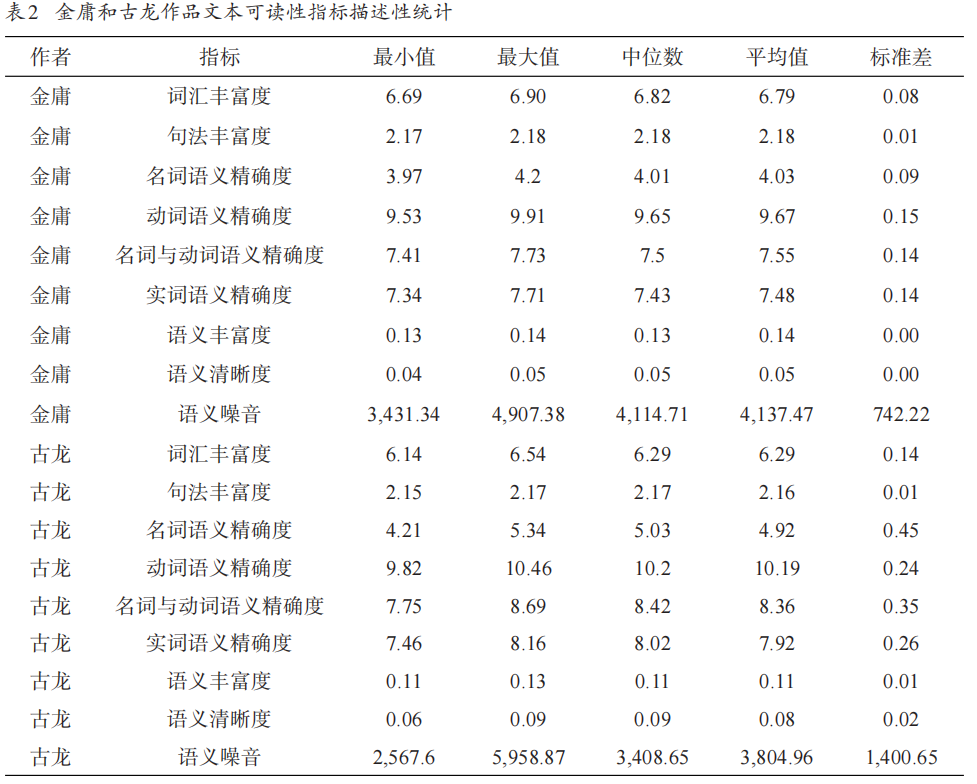
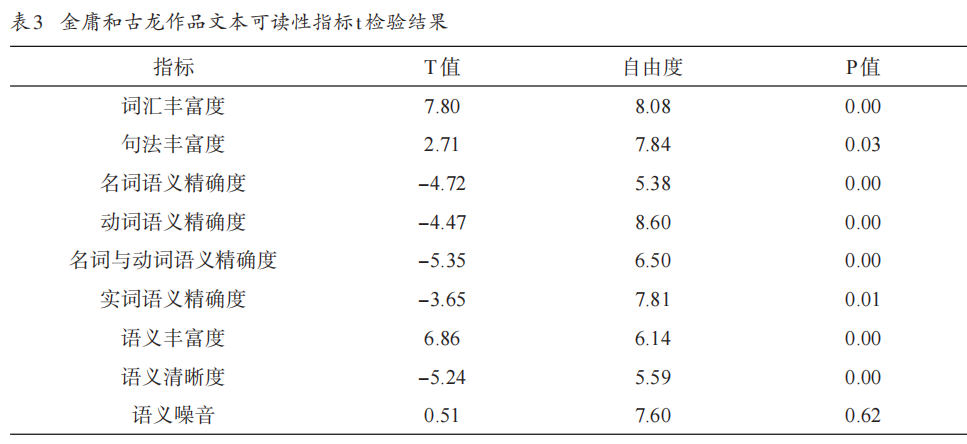
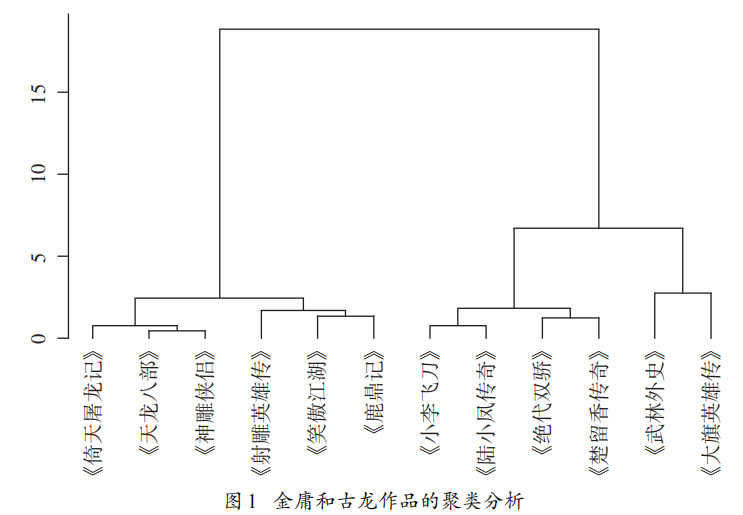
- 结果:
- 金庸作品词汇丰富度、句法丰富度、语义丰富度高于古龙,语义精确度低于古龙,表明金庸作品可读性较弱。
- T检验显示除语义噪音外,其他指标差异显著。
- 聚类分析:
- 通过汉语文本可读性工具ARC的九个指标可以很好地将两位作家的作品聚类成两个大类。
对比词长检验方法刘颖和肖天久(2014):
- 词长变化程度仅能体现文本词长的变化,而汉语文本大多由一或两个汉字构成,因此词长似乎并不能反映汉语文本的词汇丰富度。
- 本研究采用单词熵值算法,其体现的是文本词汇使用的不稳定性或变化程度,似能更好地反映文本词汇丰富度。本研究结果发现,金庸作品文本的词汇丰富度显著大于古龙作品文本的词汇丰富度,故其作品的可读性弱于古龙作品。
4. 启示与展望
- ARC优点:
- 多维度指标体系(词汇、句法、语义)。特别关注语义维度,弥补现有研究不足
- 成熟计算方法(如熵值、偏度、峰度)。
- 通用性,适用于数字人文、国际中文教育等领域。
- 少而精的思路试图在指标数量、指标质量及工具运行效率上取得平衡,即在确保ARC指标体系全面、有效的同时,又兼顾工具运行和数据处理的高效性。
- 局限性:
- 未包括语篇连贯维度。
- 未来可开发回归方程或大语言模型,进一步验证多领域适用性。