强化学习
强化学习(Reinforcement Learning)
强化学习是一种机器学习方法,它通过代理与环境的交互来学习如何做出最优决策。代理在不断尝试中获得奖励信号,并通过调整策略来最大化累积奖励。这种学习方式类似于人类通过试错来学习,帮助机器代理逐步提高在特定任务上的表现能力。
强化学习算法的思路非常简单,以游戏为例,如果在游戏中采取某种策略可以取得较高的得分,那么就进一步“强化”这种策略,以期继续取得较好的结果。这种策略与日常生活中的各种“绩效奖励”非常类似。
强化学习与监督学习的区别
训练数据中没有标签,只有奖励函数(Reward Function)
训练数据不是现成给定,而是由行为 (Action)获得
现在的行为 (Action)不仅影响后续训练数据的获得,也影响奖励函数 (Reward Function)的跟值
训练的目的是构建一个“状态一>行为”的函数

离散状态空间
示例:火星探测器
探测器在火星执行探测任务,共有 6 个位置。在强化学习中,探测器的位置被称为状态,初始时,探测器位于状态 4。
现在,位置 1 和位置 6 都有一些有趣的表面。科学家希望探测器对位置 1 进行采样,因为它比位置 6 更重要。但是位置 1 很远,所以我们通过奖励函数来反映状态的价值,在每个状态可以获得对应的奖励。状态 1 的奖励是 100,状态 6 的奖励是 40,其他状态的奖励都是 0。在每一步中,探测器可以选择向左或向右移动。
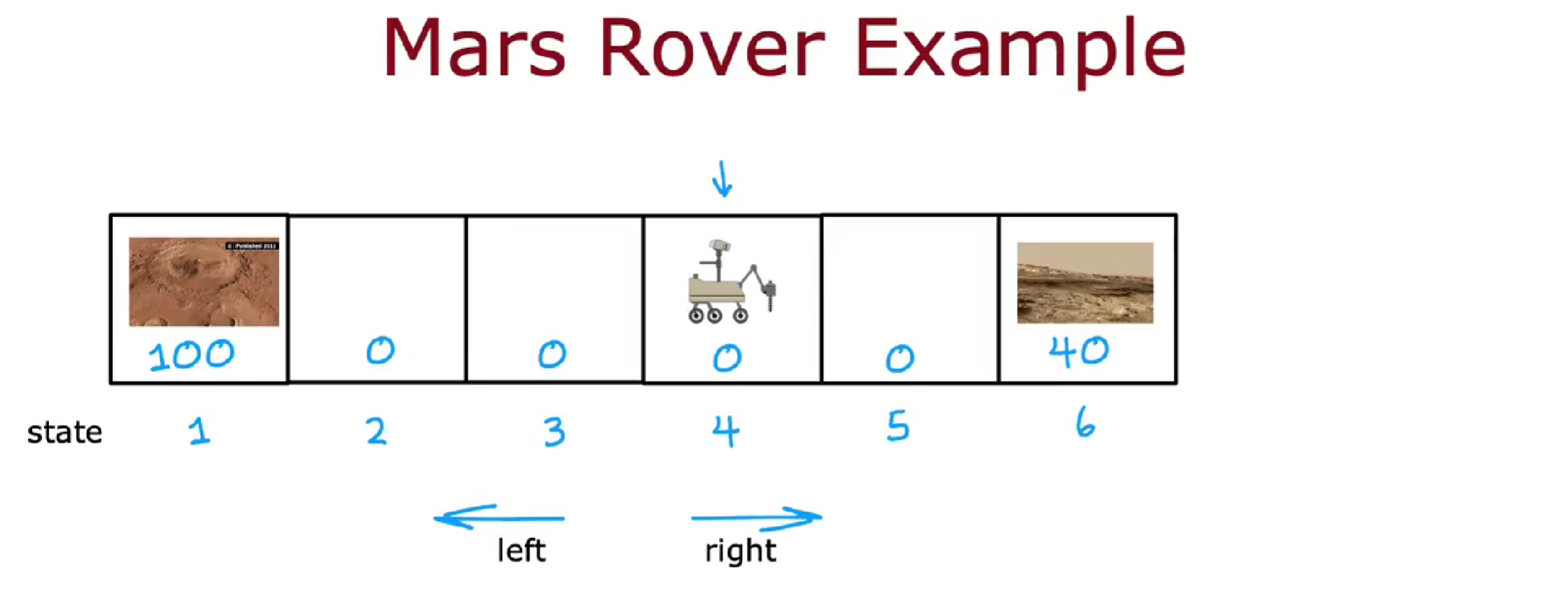
在每个位置,机器人都处于某种状态 s,它可以选择一个动作 a,并从而得到奖励 R (s),状态随动作变为新的状态 s'。注意,奖励 R (s)是与状态 s 相关,而不是下一个状态 s'相关。
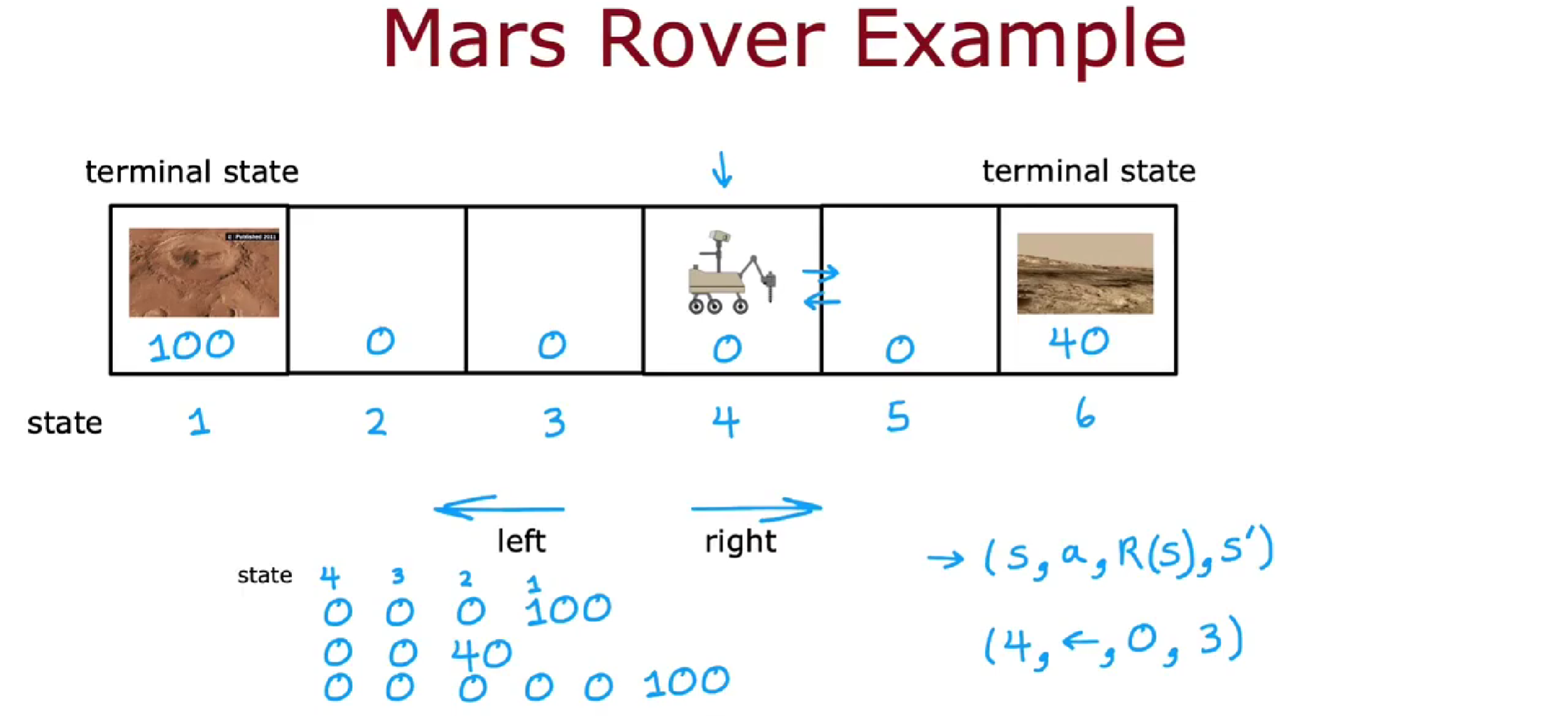
例如,当探测器处于状态 4,并采取了向左走的动作,状态 4 奖励为 0,变为新的状态 3。
强化学习四要素:状态、动作、奖励、下一个状态
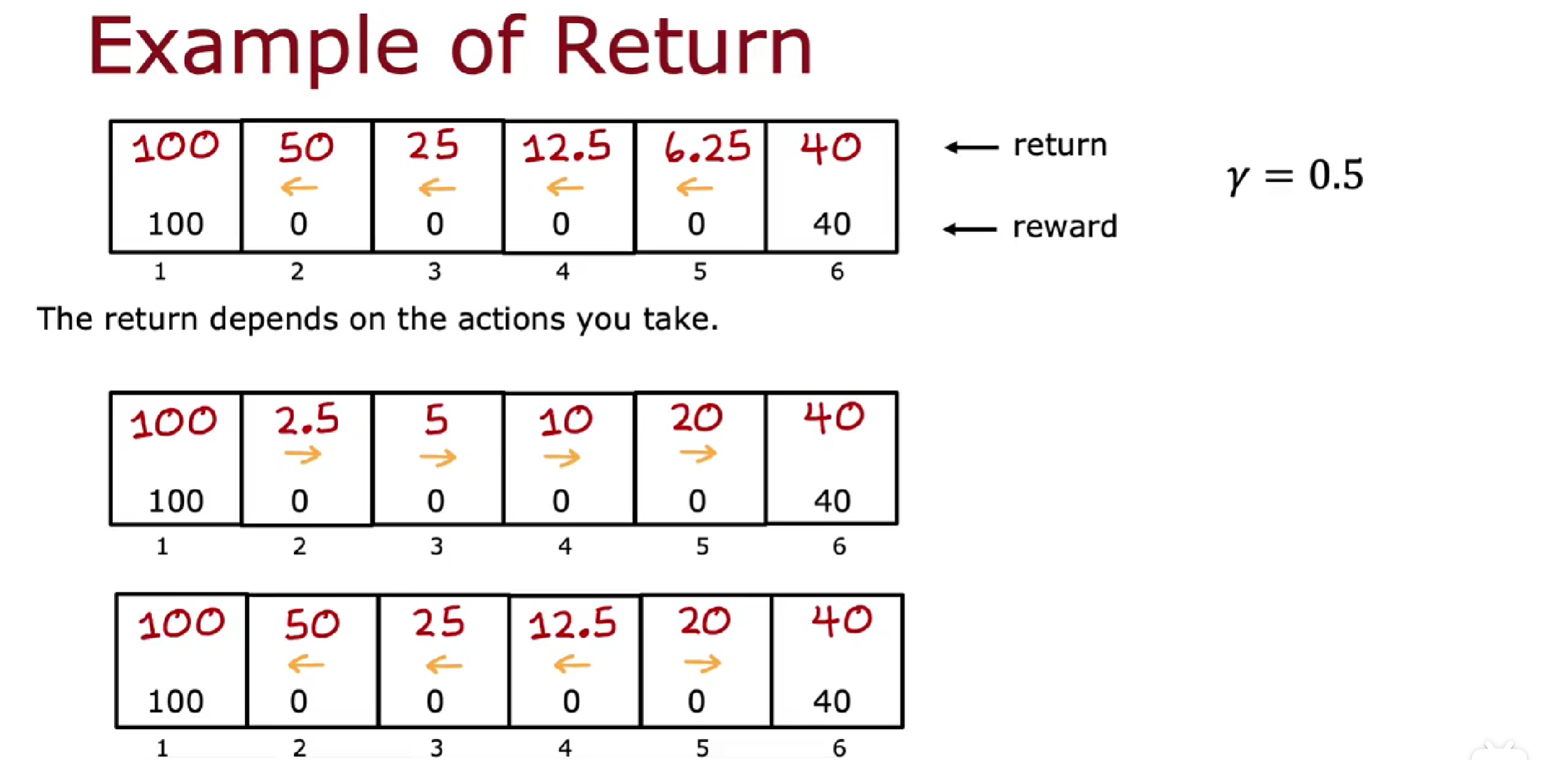
探测器在不同的位置可以走不同的路线,起点为位置 4 可以走 4-3-2-1,也可以走 4-5-6。较远的位置虽然奖励多,但是它所花费的时间和路程值得这些奖励吗?怎么知道一组特定的奖励比另一组不同的奖励更好还是更差?
我们用强化学习中的回报(Return) 来解决这件事。
回报
基于折扣因子和奖励值,计算一系列动作下所获得的总效用值。折扣因子
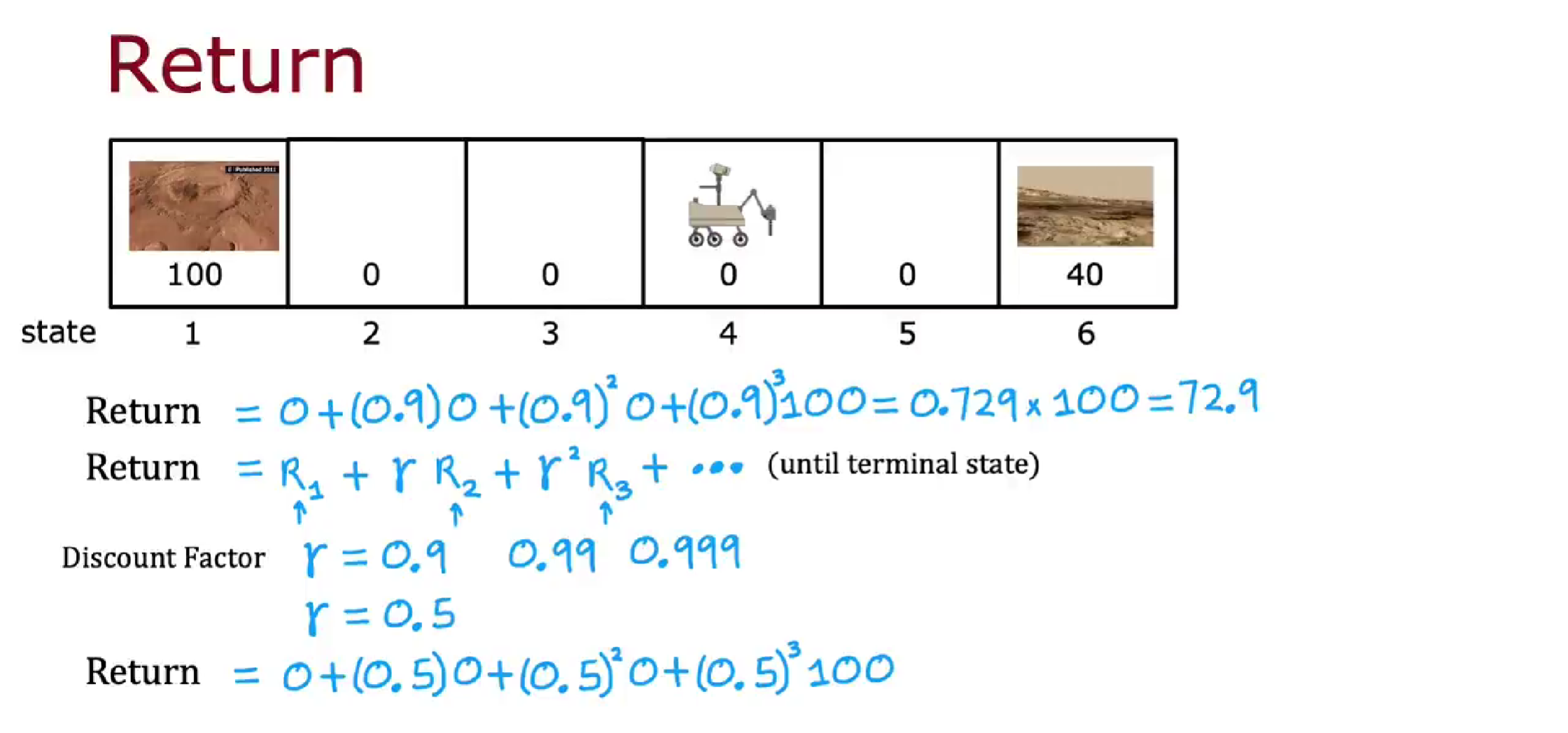
得到的回报取决于奖励,而奖励取决于你采取的行动,因此回报取决于你采取的行动。
策略
策略(policy)是指代理在特定状态下选择动作的方式或规则。策略定义了代理对于给定状态所做出的行为,就是一个从状态到行为的映射。我们可以通过策略来确定每个状态下的行为。
强化学习的目标是训练出一个策略函数,它以任意状态 s 为输入,并将其映射到采取的某个动作 a。
例如可以有 4 种策略,以最后一种策略为例,右边是策略函数

强化学习的目标是找到一个策略
马尔可夫决策过程
马尔可夫决策过程
马尔可夫决策过程(Markov Decision Process, MDP),指未来仅取决于当前状态,而不取决于当前状态之前发生的任何事情。换句话说,在马尔可夫决策过程中,未来只取决于你现在所处的位置,而不取决于你是如何到达这里的。

根据目标当前状态 s,基于策略选择动作 a,世界或环境会发生变化,然后观察基于世界状态,目标的状态 s 及得到的奖励 R
状态动作价值函数 Q (s, a)
状态动作价值函数 Q (s, a)(也称为 Q-value 函数)是在强化学习中用于评估在给定状态 s 下采取动作 a 的价值的函数。它表示了代理在特定状态下采取某个动作所能获得的预期累积回报。
具体而言,对于给定的状态动作对 (s, a),Q (s, a) 表示从状态 s 开始,采取某一行动,之后一直按照最佳的策略行动,最终获得的预期累积回报。这个预期累积回报通常是通过累加未来奖励的折扣值来计算的。(至于为何能在获得最优策略前计算 Q,后面会讲,会基于循环)。

例如:
计算 Q(2,→),则为以状态 2 开始,采取向右的行动,到状态 3,那后面最优策略是一直向左走,行动轨迹为 2-3-2-1,所以计算 Q 为 12.5。
Q(2,←)则为以状态 2 开始,采取某一行动为向左,行动轨迹为 2-1,此时 Q 为 50。
对每个状态,每个动作,都可计算得到 Q。而且我们可以发现,Q (s, a)的最大值即为从状态 s 获得的最佳可能回报。因此当我们可以计算 Q (s, a),即可知道最佳的动作。
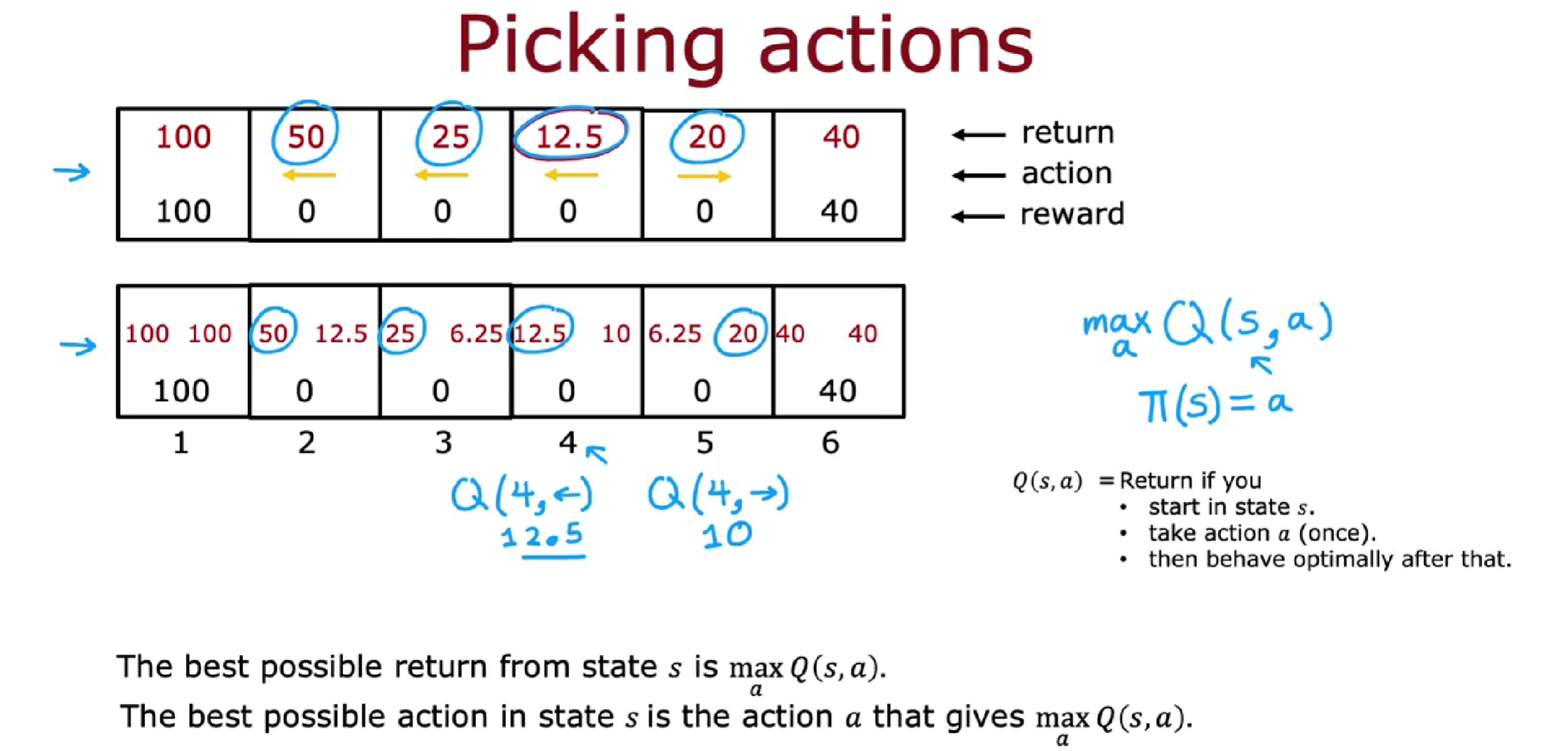
如果你可以计算每一个状态每一个动作的 Q (s, a),然后找出最大的 Q (s, a),这个 Q (s, a)中的 a 即为最佳的行动,所以该状态 s 的
因此,Q 计算和策略相对应,如果能基于 s 和 a 计算 Q 函数,就能得到策略。
贝尔曼方程
贝尔曼方程(Bellman equation)是强化学习中的关键方程,用来描述状态值函数或者状态动作值函数之间的递归关系。
贝尔曼方程:
贝尔曼方程通过将当前状态和动作的价值与下一个状态的价值联系起来,帮助我们计算最优策略。也就是说,贝尔曼方程告诉我们一个状态的价值如何与其后续状态的价值相关联。
贝尔曼方程的本质是,当前状态 s 的总回报包含两部分,一部分是马上得到的奖励 R (s),第二部分是

例如从状态 4 开始,向左走:
实际上,贝尔曼方程告诉我们,在当前状态下采取某个动作的价值与下一个状态的价值之间存在一个关系。通过不断迭代更新这个关系,最终将能够找到最佳策略,即在每个状态下都选择可以获得最大预期回报的动作。
随机马尔可夫决策
在随机马尔可夫过程中,执行动作 a 时,存在一定概率无法按照预期进行。以一个随机环境为例,我们向一个探测器发送左转指令,但由于未知的环境因素,左侧地面可能很滑,导致探测器滑向相反的方向,无法按照我们的指令执行。因此,我们获得的奖励也是随机的。
在随机强化学习问题中,目标的不是最大化回报,而是折扣奖励总和的平均值,即期望回报
随机马尔可夫决策中,贝尔曼方程改为:

前面 TensorFlow 实例中,misstep_prob 参数就表示失误概率。
连续状态空间应用
例如在自动控制汽车、飞机中,状态 s 都是连续状态空间,包含 x, y, z 轴坐标,及各轴方向上速度、角速度等,这都是连续状态空间
示例:登月器
登月器的任务是在适当的时候启动火力推进,将其安全降落到着陆台上。
状态:
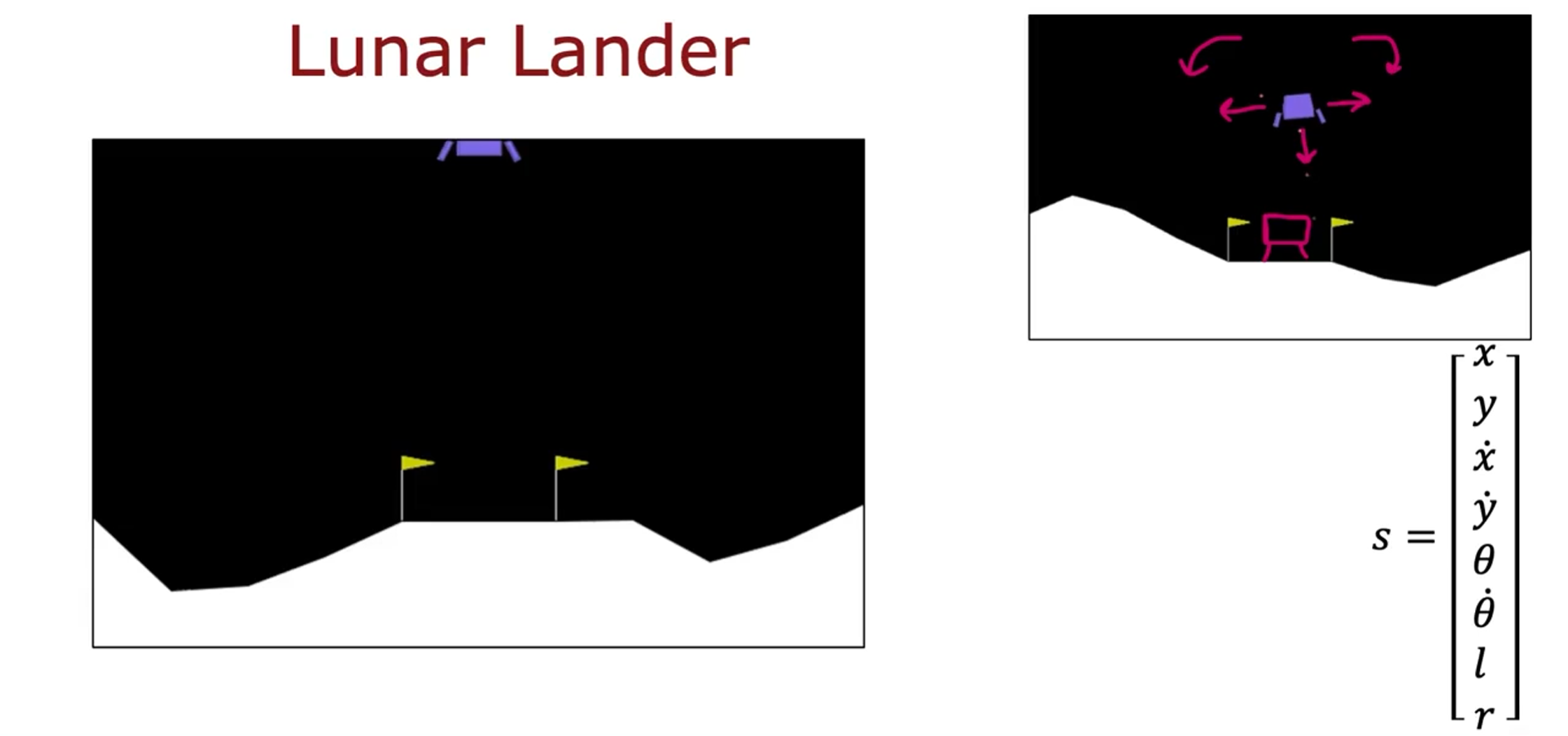
动作: 什么都不做,向下加速,向左加速,向右加速
奖励函数:

到达着陆台:100-140
靠近/远离着陆台的额外奖励
坠毁:-100
软着陆:+100
腿着陆:+10
启动主推进器:-0.3
启动侧推进器:-0.03
目标是找到策略函数:
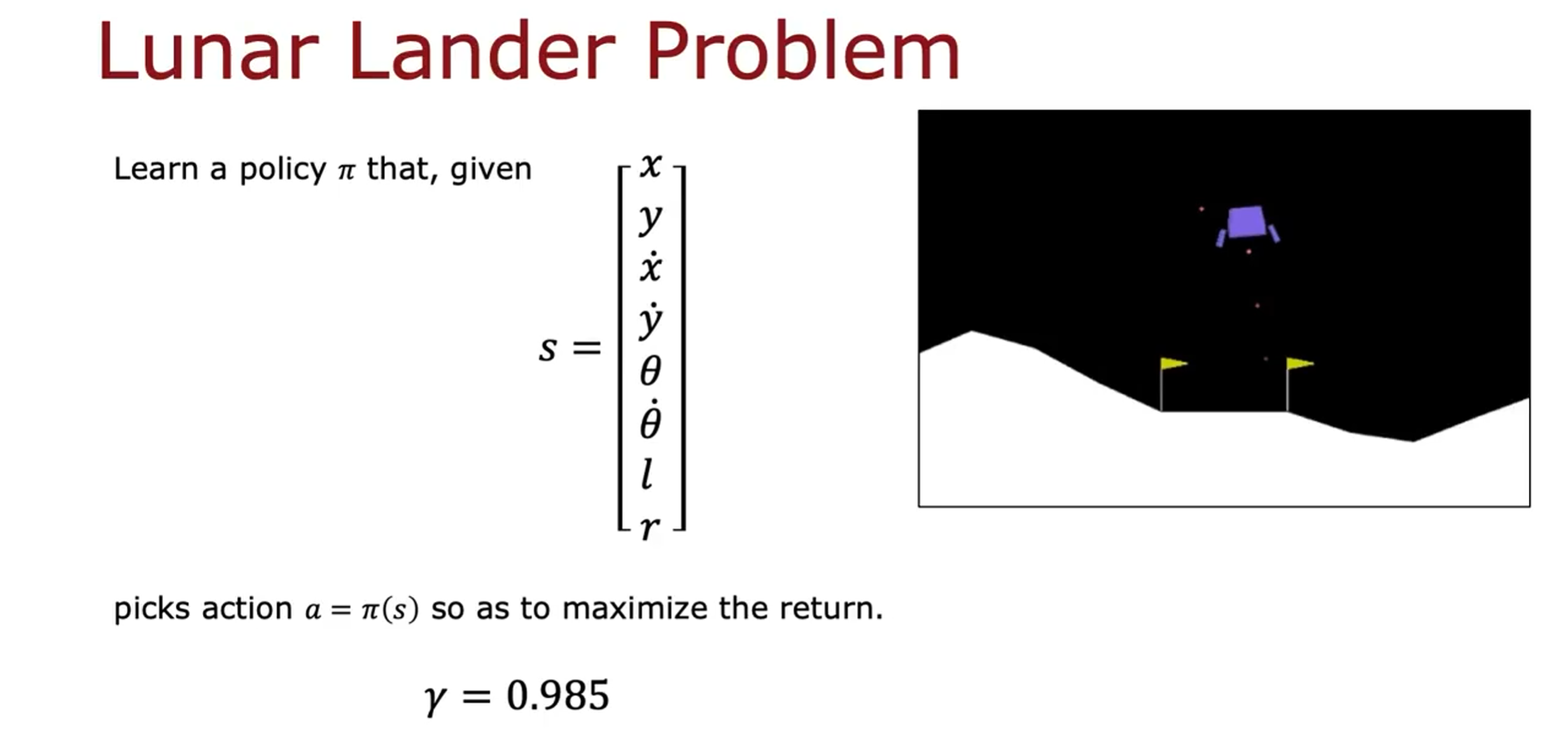
学习状态值函数(强化学习中使用神经网络)
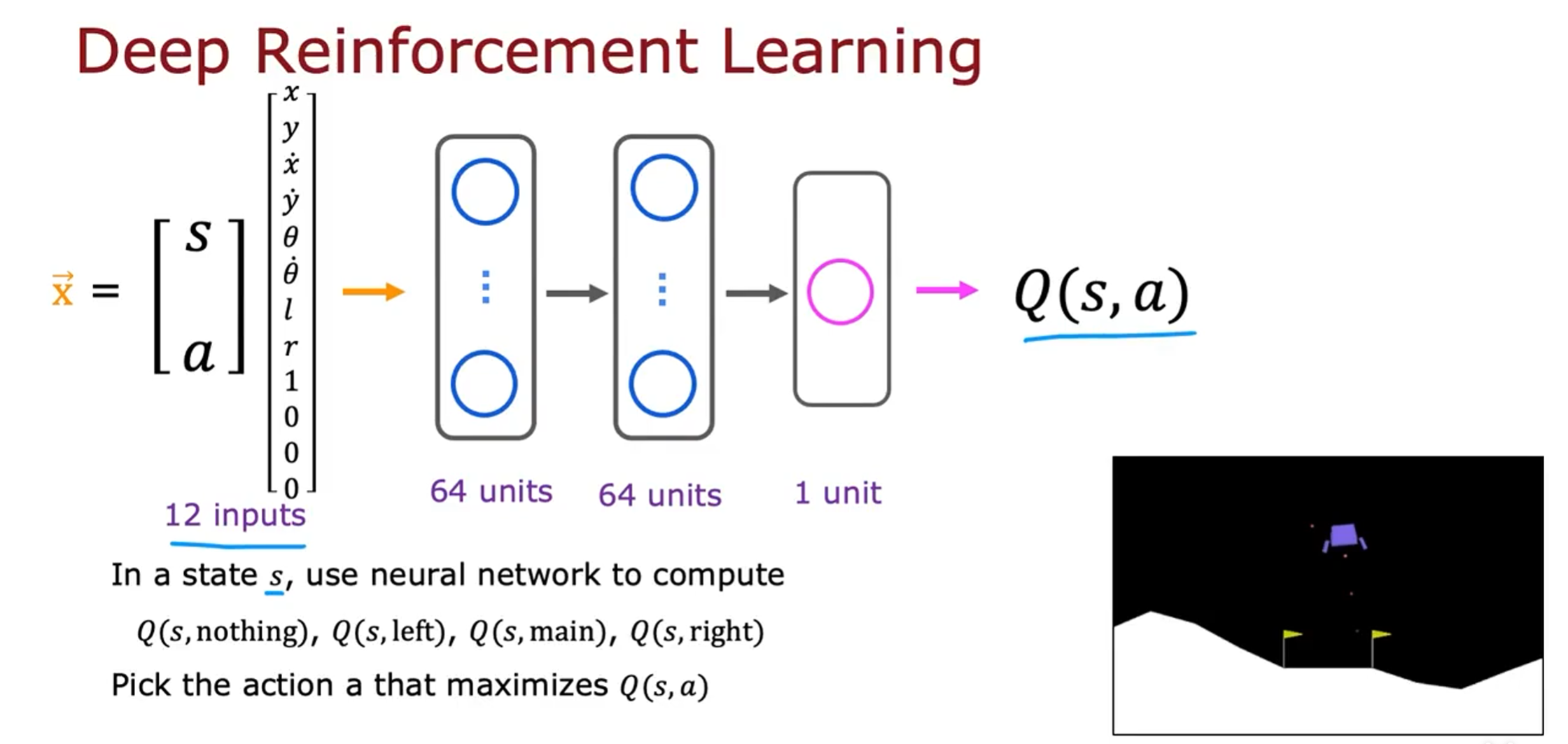
关键思想是我们要训练一个神经网络来计算或近似 S, a 的状态动作值函数 Q, 然后上我们选择好的动作
学习算法的核心是我们将训练一个神经网络,该网络输入当前状态和当前动作并计算或近似的 Q 。
我们将状态和动作放在一起作为输入,这个 12 个数字的列表,8 个数字用于状态,然后是个数字是动作的独热编码。这是我们对神经网络的输入,称之为 X。神经网络的工作就是输出 Q。
因为我们稍后会使用神经网络训练算法,所以我还将 Q 作为训练神经网络逼近的目标值 Y。强化学习与监督学习不同,但我们要做的不是输入状态并让它来输出动作。我们要做的是输入一个状态动作对,让它尝试输出 Q, 并在强化学习算法中使用神经网络。
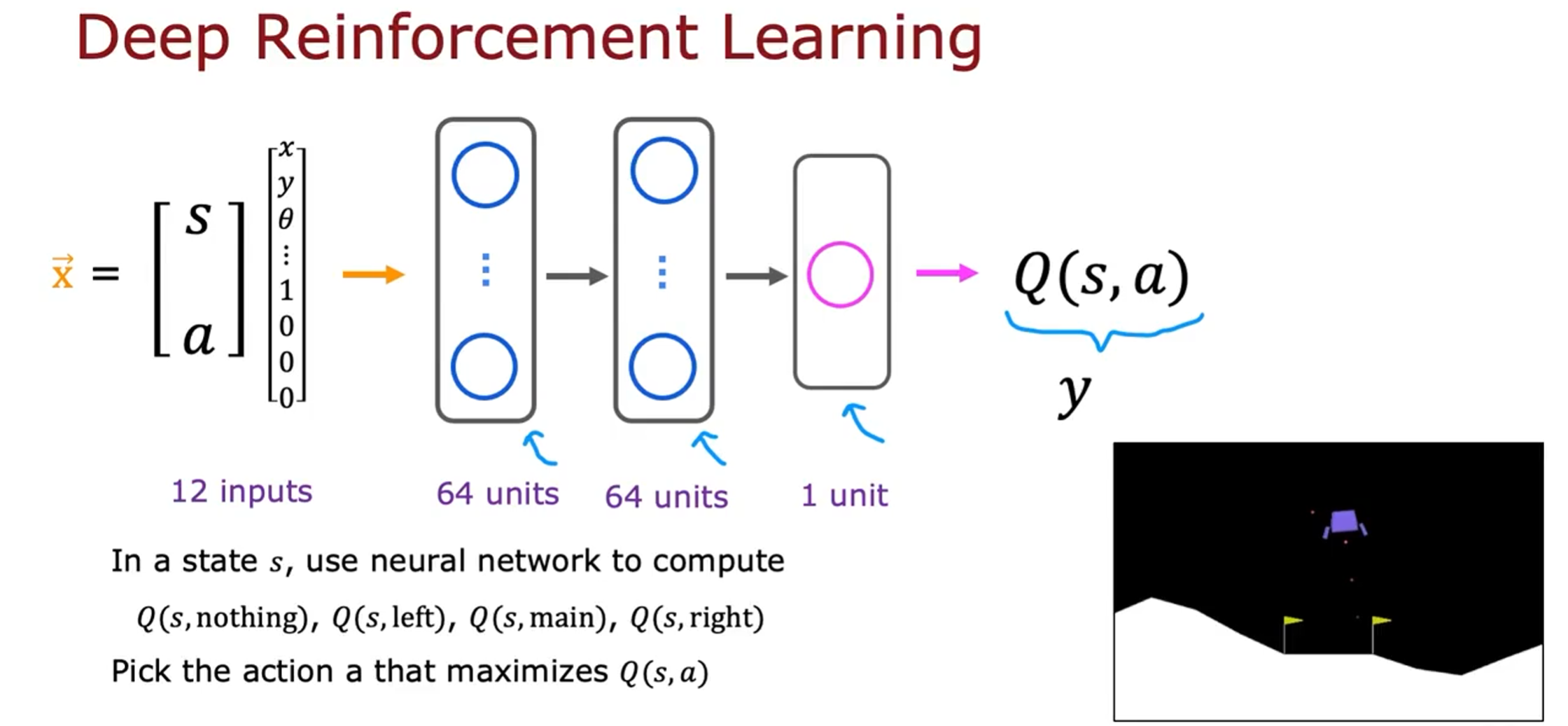
如果您可以在隐藏层和上层中选择适当的参数来训练神经网络,以便为您提供对 Q 的良好估计,那么每当您在月球着陆器处于某种状态 s 时,您就可以使用神经网络计算 Q。对于所有四个动作,都可以计算 Q,Q (s, nothing), Q (s, left), Q (s, main), Q (s, right),最后,哪个具有最高值,就选择那个相应的动作。
例如,如果在这四个值中,Q (s, main)最大,那么将启动着陆器的主推进器。
所以问题就变成了,如何训练一个神经网络来输出 Q?
方法是使用贝尔曼方程来创建包含大量示例x和 y 的训练集,然后我们使用监督学习,就像神经网络时所学的一样。使用监督学习,利用神经网络学习从 x 到 y 的映射,即从状态动作对到目标值 Q 的映射。
但是,如何获得具有 x 和 y 值的训练集,可以在其上训练神经网络?
这是贝尔曼方程:
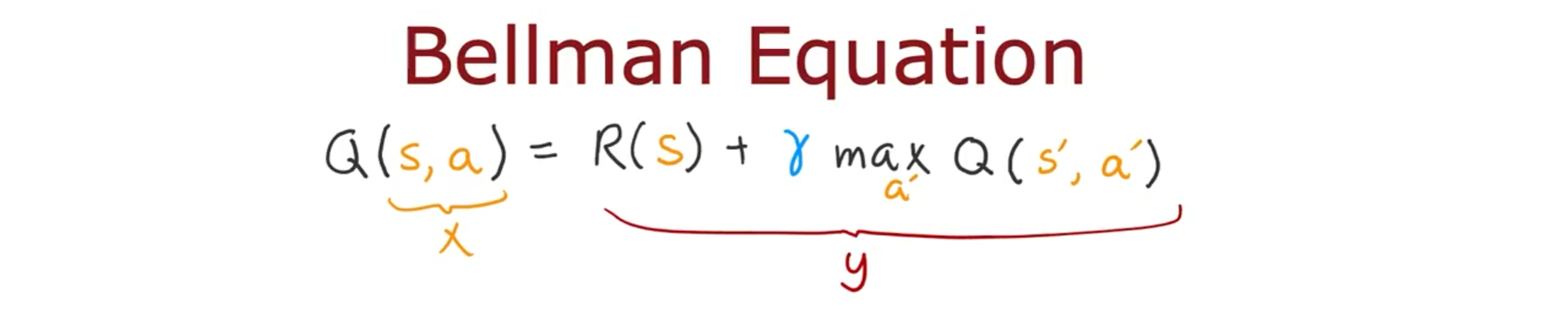我们将等式右边的值为神经网络的输出 y,等式左边即为输入 x。神经网络的工作是输入 x,即输入状态动作对,并尝试准确预测右边的值。
在监督学习中,我们训练一个神经网络来学习一个函数 f,它取决于参数 W 和 B(神经网络各个层的参数),神经网络的最左端输入 X,最右端放一些接近目标值 y 的东西。
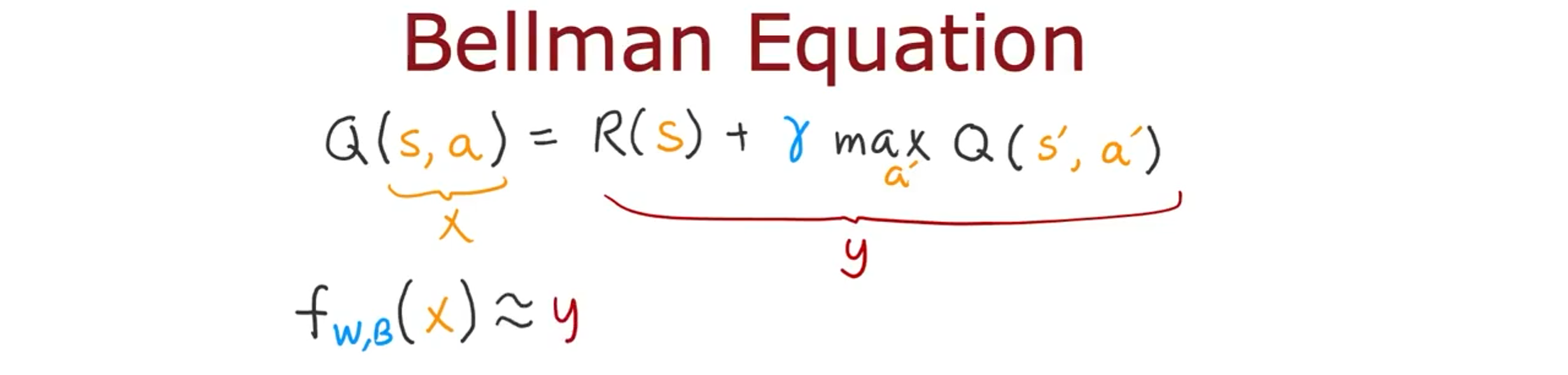
问题是,我们如何才能为新网络提供一个具有 x 和 y 的训练集来学习?
我们将使用着陆器,并尝试在其中随机执行不同的操作。通过在月球着陆器中尝试做不同的动作,我们将会得到很多例子,这些例子说明我们何时处于哪种状态并采取了哪些动作,可能是一个好的动作,也可能是一个坏的动作。然后,由于处于该状态,我们获得了一些奖励 R (s),接着,我们进入了某个新状态 S'。

例如,也许有一次处于某个状态
也许在不同的时间处于某个状态
也许你已经这样做了 10,000 次甚至超过 10,000 次。这 10,000 个元组都是训练示例 x,y。

元组中的前两个将用于计算 x,后两个将用于计算 y。
例如,
贝尔曼方程表示,当您输入
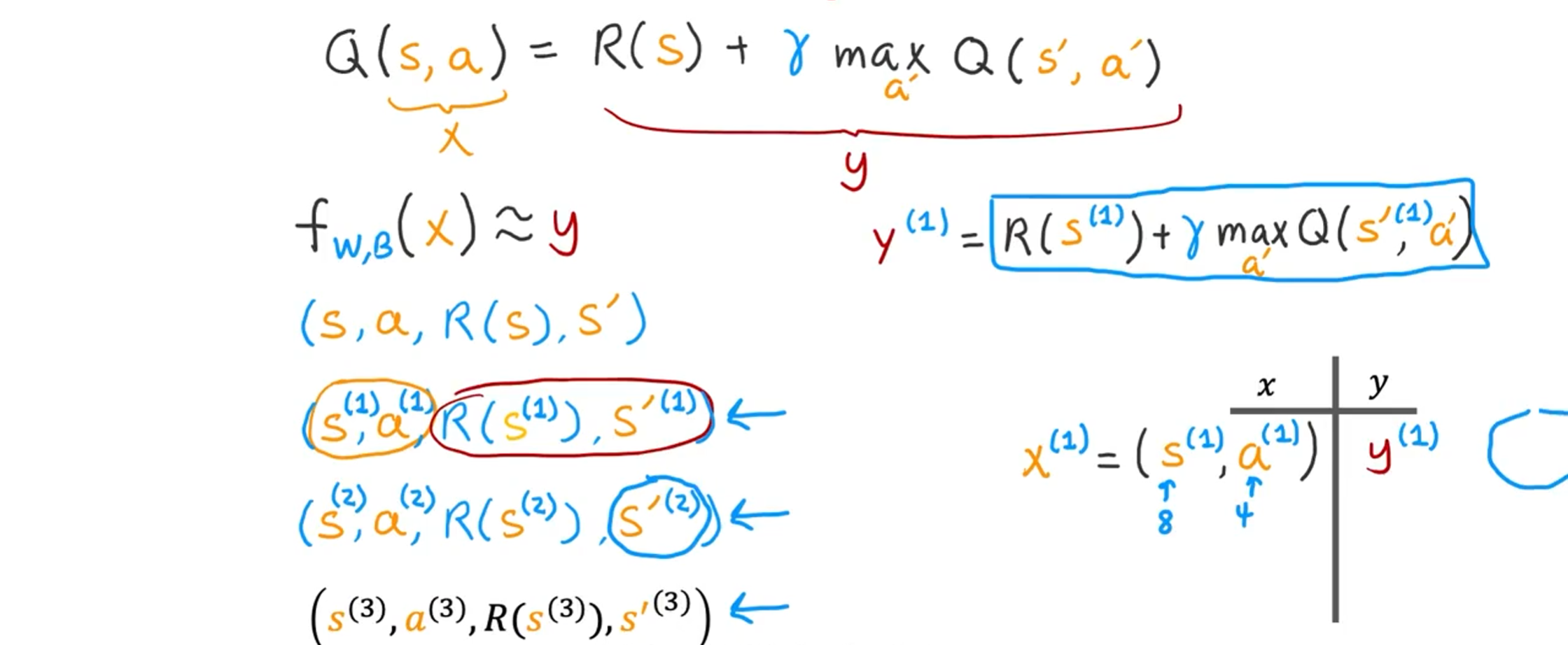
现在你可能想要知道
依此类推,直到你最终得到 10,000 个包含这些 x, y 对的训练示例。稍后,我们将采用这个训练集,其中 x 是具有 12 个特征的输入,而 y 只是数字。 我们将使用均方误差损失来训练一个新网络,以尝试将 y 预测为输入 x 的函数。
以上描述的只是我们将使用的算法的一部分,接下来看看它们是如何组合成一个学习 Q 函数的完整算法的。
首先,我们将采用我们的神经网络并随机初始化神经网络的所有参数。最初我们不知道 Q 函数是什么,我们只是完全随机的赋值。我们假设这个神经网络是我们对 Q 函数的初始随机猜测。这有点像你在训川练线性回归时随机初始化所有参数,然后使用梯度下降来改进参数。现在随机初始化没关系。重要的是算法是否可以慢慢改进参数以获得更好的估计。

接下来,我们将重复执行以下操作;我们将对着陆器中采取动作,然后得到众多元组

日前,我们只是让月球着陆器随机飞行,有时会坠毁,有时不会坠毁,并根据学习算法经验获取这些元组。
有时我们会训练神经网络,为了训练神经网络,下面是我们要做的。
我们将查看我们保存的这 10,000 个最近的元组,并创建一个包含 10,000 个示例的训练集。
训练集需要很多对 x 和 y。对于我们的训练示例,x 将是 s 来自元组的

创建这 10,000 个训练示例后,我们将拥有训练示例

事实证明,如果您从真正随机猜测 Q 函数开始运行此算法,然后使用 Bellman 方 Set-new. 程反复尝试改进 Q 函数的估计值。, 9 然后通过反复执行此操作,采取大量操作,训川练模型,这将改进您对 Q 函数的猜 Set-new. Jw, BX) XU 测., 9 对于您训川练的下一个模型,您现在对什么是 Q 函数有了更好的估计。那么你训练的下一个模型会更好当您更新 Q 等于 Qnew 时。然后下次训练
当你在每次迭代中运行这个算法时,
这个算法称为 DQN 算法(Deep Q-Network),因为使用深度学习和神经网络训练模型来学习 Q 函数。
算法改进:改进的神经网络架构
改进前,神将网络只能输出一个值,要分别计算 4 次 Q,Q (s, nothing), Q (s, left), Q (s, main), Q (s, right)各一次
改进后,神经网络可以同时输出四个值,会更加有效,且更方便选择最大值,可直接用于贝尔曼方程计算

算法改进:Epsilon Greedy 策略
ε-greedy 策略是一种在强化学习中常用的策略,用于在探索(exploration)和利用(exploitation)之间进行权衡。该策略基于一个参数ε,用来决定代理在选择动作时是进行随机探索还是根据当前已学习的知识做出最优动作的利用。

在强化学习中,ε-贪婪策略(方法 2)是更常用的方法。在大多数情况下,我们选择使当前的 Q (s, a)(神经网络训练出来的)最大化的动作 a,即贪婪行动。只有在极少数情况下(偶尔)会随机选择动作,即探索行动。
方法 1 容易出现问题,因为由于随机初始化的原因,可能始终不会尝试一些动作,而这些动作可能会效果很好。为了解决这个问题,我们采用方法 2,即使用ε-贪婪策略,对所有动作进行尝试。
当ε=0.05 时,贪婪动作占 95%,探索动作占 5%。
通常,在学习刚开始时,我们将ε设置得较大,这样代理会频繁地选择随机动作,然后逐渐减小ε的值,因此随着时间的推移,代理不太可能随机采取行动,而更有可能根据 Q 函数来选择最优的动作。
在强化学习中,参数的选择非常关键,不合适的参数选择可能导致训练时间非常非常慢。
算法改进:小批量和软更新
小批量(mini-batches)可以提高算法运行速度,同样适用于监督学习,例如训练神经网络,或训练线性回归或逻辑回归模型。
软更新(soft updates)可以使强化学习更好的收敛
小批量
小批量是指在训练模型时,将训练数据划分为多个较小的批次进行模型参数的更新。相比于使用完整的训练集进行参数更新,小批量更新可以提高计算效率,并且有助于减少参数更新的方差。
当样本数量非常大时,例如有一亿个样本,如果梯度下降的每一步都需用全部样本计算平均值,那么算法会运行的很慢。使用小批量是每次梯度下降时,只关注一个 batch 的数据。使用小批量梯度下降的思想是不用再每次迭代中使用 1 亿个示例,而是选择一个较小的数,如 1000,这将花费较少的时间。

小批量梯度下降很容易在迭代时向着错误的方向前进,不可靠且有点嘈杂。但会趋向于全局最小值,每次迭代的计算成本要低得多,因此小批量梯度下降可以提高算法运行速度。
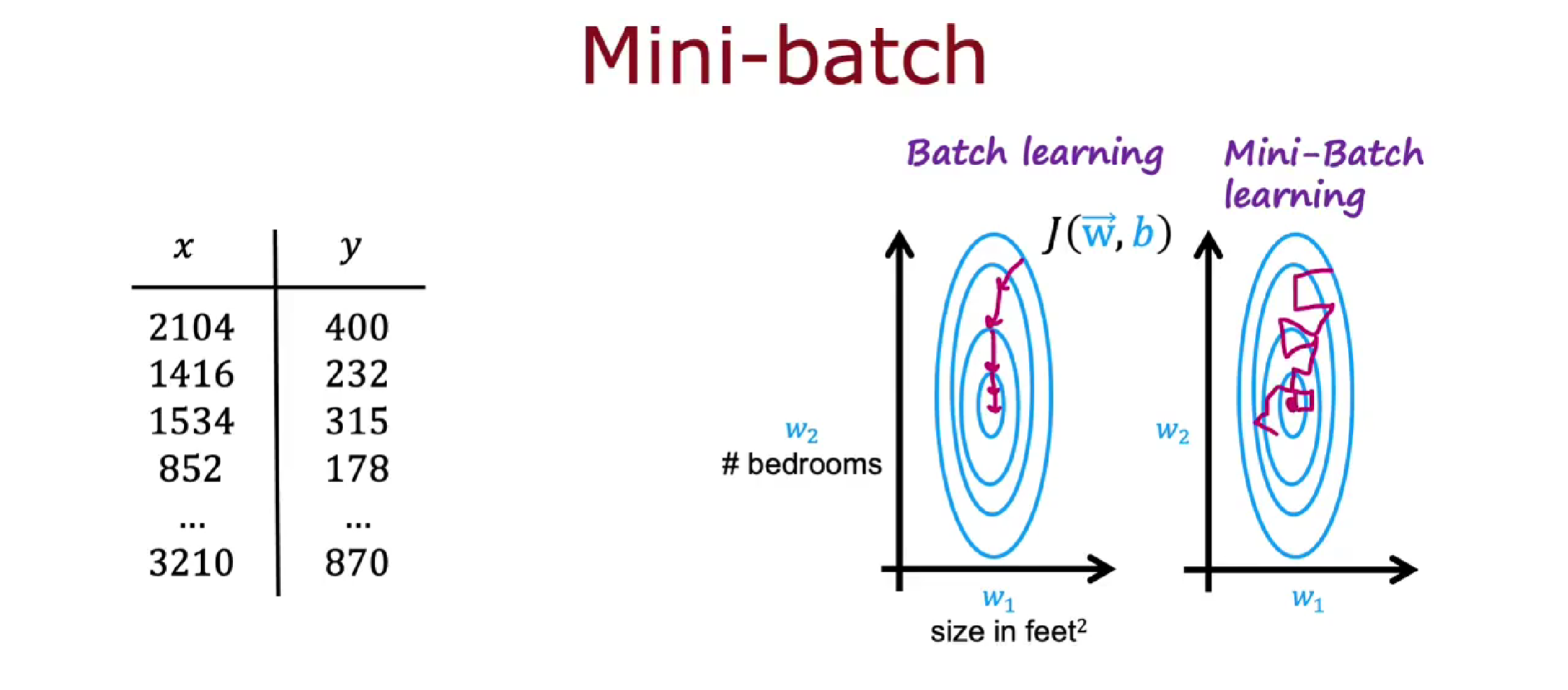
在强化学习中同样可以应用 mini-batch,如虽然缓冲存储区中有 10000 个样本元组,但每次训练神经网络模型时可以只选取 1000 个(一个 batch)来进行训练

软更新
软更新是指在深度强化学习的策略网络和目标网络之间进行参数更新时,采用一种平滑的更新方式。
在软更新中,每次更新时只更新一小部分的策略网络参数,而不是完全替换目标网络的参数。这样可以缓解训练过程中目标网络参数的剧烈变化,使得网络更新更加稳定,更好的收敛。
软更新通常使用一个超参数τ来控制更新的幅度,即通过对新参数和旧参数进行加权平均来更新目标网络的参数。

强化学习发展现状
- 强化学习在模拟状态实现要比真实状态实现容易很多
- 应用要比监督学习和无监督学习少很多
- 前景很大,是机器学习的支柱之一
