过拟合
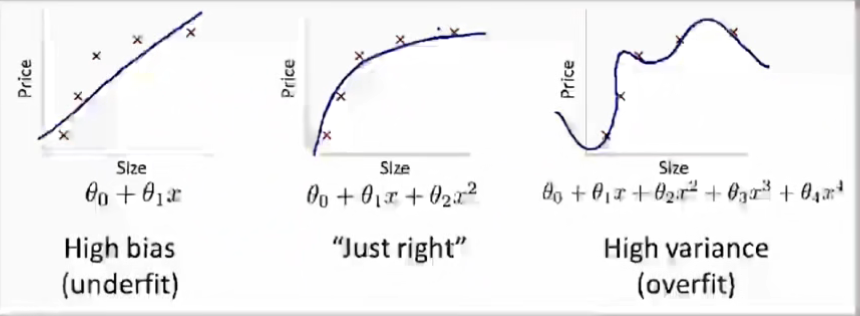
欠拟合——过拟合(预测函数复杂度高于训练数据复杂度的情况)
过拟合指的是模型学习数据时,不仅记住了数据中的细节,还把偶然出现、不重要的东西(即“噪声”)同时记住了。
过拟合
欠拟合、过拟合
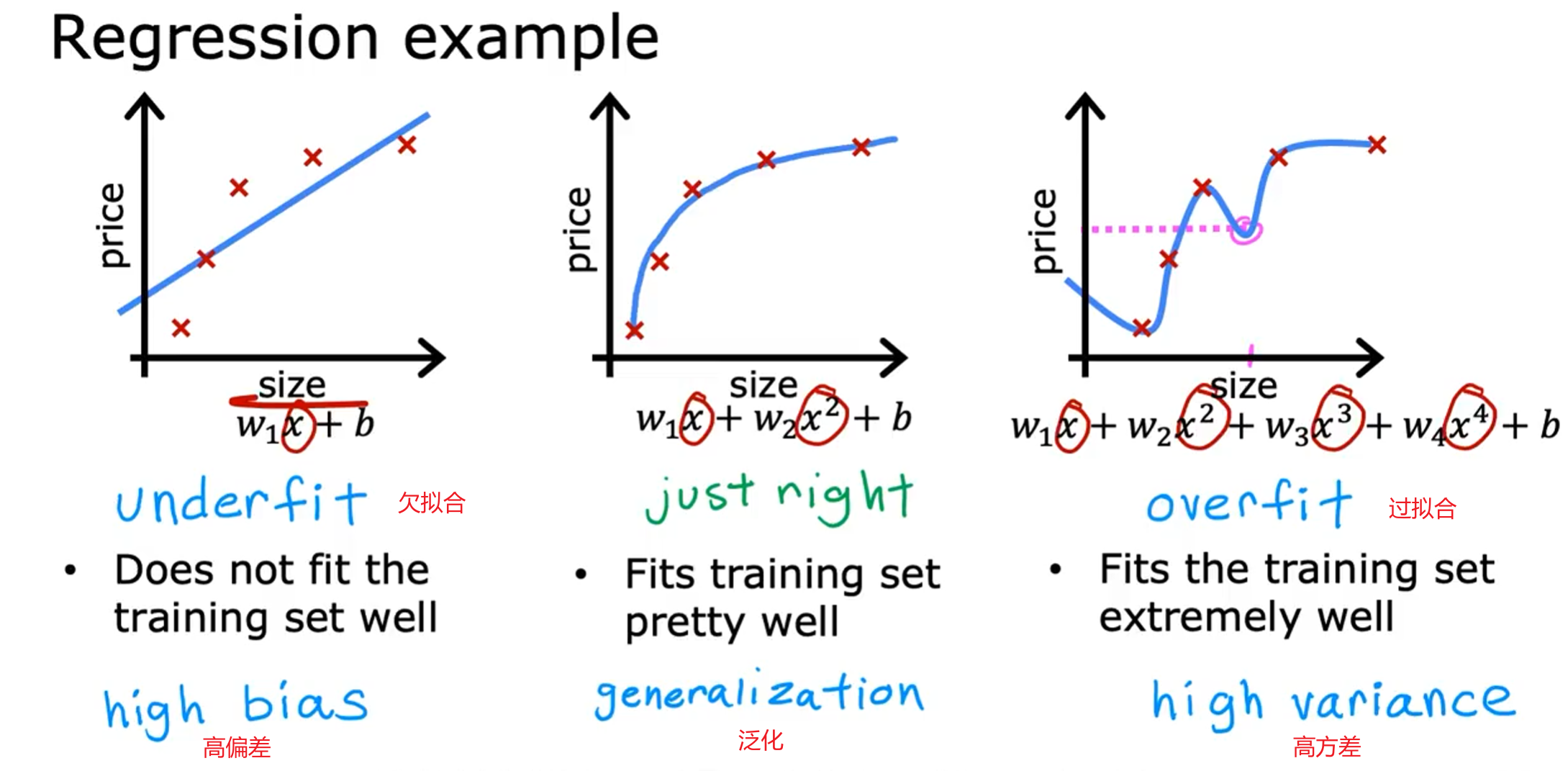
左图,欠拟合(underfit),也称作高偏差(High-bias),即对于当前数据集的拟合程度不够,欠拟合的特征是在训练集和测试集上的准确率都不好;
中图,拟合刚好的状态,具有泛化能力;
右图,过拟合(overfit),也称作高方差(High variance),过拟合对于当前训练数据拟合得太好了,以至于模型只在当前的训练集上表现很好,而在其他数据集上表现就不是那么好,所以过拟合的特征是在训练集上准确率很高而在测试集上表现一般。
解决过拟合
方法:
通过偏差与方差评估过拟合与欠拟合 模型任务评价指标#偏差与方差
当出现过拟合问题的时候,可以考虑
- 数据集问题:提升数据集质量/数据集过多
- 微调问题:学习轮次与数据条数不匹配,学习轮次过多
主观的标准:根据自己对产品的预期,确定预期目标效果的评估框架。这是最重要的
客观的标准:查看loss曲线。
Loss曲线是用于评估模型学习状态(学习损失)的曲线。